
인프라 모니터링은 현대의 IT 시스템에서 매우 중요한 역할을 합니다.
이는 시스템의 성능, 가용성 및 안정성을 유지하기 위해 필수적으로 수행되어야 합니다.
인프라 모니터링에 많은 제품이 있지만 가장 많이 사용되는 Prometheus 기반의 모니터링을 알아보겠습니다.
서비스 운영 중 발생할 수 있는 이슈 및 오류에 대비하기 위해 관련 데이터를 수집하고 기록하는 것입니다.
메트릭(Metrics)은 시스템, 애플리케이션 또는 네트워크와 같은 IT 환경에서 측정 가능한 수치나 지표를 의미하며, 모니터링 시스템에서는 대상(Target)의 시스템 정보 또는 특정 프로세스의 메트릭을 가져옵니다.
메트릭을 가져온다고 했지만 이것은 “Pull-based monitoring system”에 적용되는 개념입니다.
모니터링 방식에는 2가지 방식이 존재합니다.
Prometheus는 대상(Target)으로부터 메트릭 값을 받아오는 모니터링 시스템즉, Pull-based monitoring system입니다.
Pull 기반은 Target에 직접적으로 접근하여 데이터를 Scraping 하며 그 대상이 되는 Target은 데이터를 노출 시킬 방법이 필요하며 Prometheus는 이러한 니즈에 대해 생태계가 잘 구축되어있습니다.

이러한 특징을 가지고있지만 가장 큰 이유는 “다양하고 직접 개발이 가능한 Exporter” 와 “Kubernetes 환경의 모니터링” 정도입니다.

지금부터 본격적으로 Prometheus기반 모니터링 생태계를 하나하나 살펴보겠습니다.

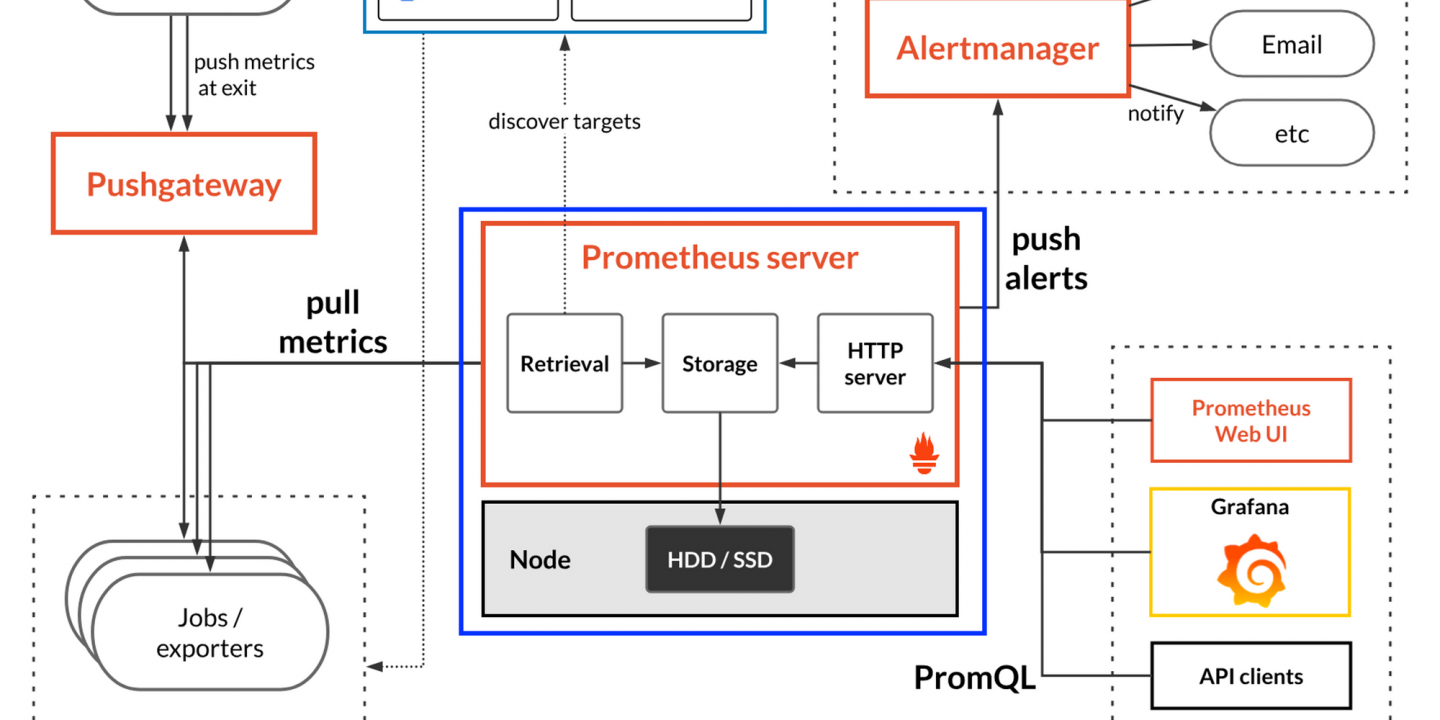
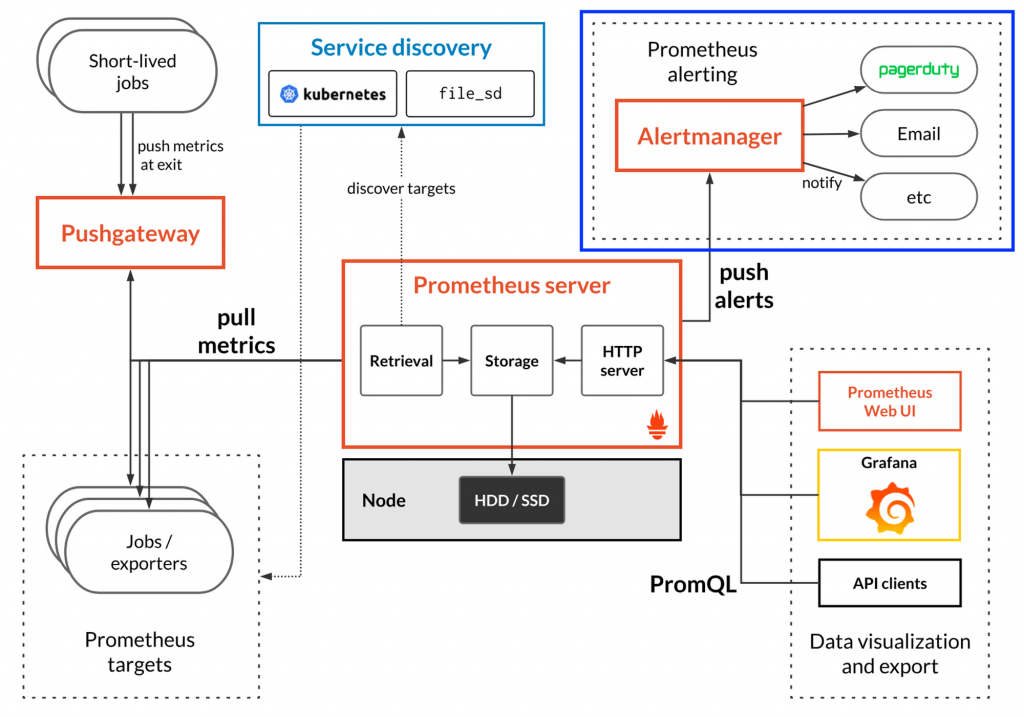
먼저 데이터를 수집하기 전에 어떠한 데이터를 가져올 것인지 알아야 합니다.
프로메테우스 서버를 이루는 요소 중 하나인 Retrieval에서 Service discovery에 정의되어 있는 Target을 식별합니다.
Service discovery는 Target을 yaml 형태로 정의한 파일로 저장되어 있으며 메트릭을 수집할 대상을 동적으로 설정하는 것을 가능하게 해주고 이를 통해 Auto-Scale 되는 Virtual Machine EC2 Instance 그리고 Kubernetes Cluster로부터 메트릭 수집을 가능하게끔 도와줍니다.
Target이 정의되면 Retrieval에서 Target에 존재하는 Exporter를 통해 메트릭을 스크래핑 합니다.

시스템의 정보를 수집하고 HTTP endpoint로 메트릭을 노출시켜주는 기능을 가지고 있습니다.
exporter는 설치형 에이전트이며 누군가 개발한 export를 설치하거나 자신이 개발하여 사용할 수 있습니다.
AWS RDS, ELB같은 Cloud Provider 관리형 서비스에는 설치가 불가능합니다.
아래는 exporter가 어떻게 HTTP 엔드포인트로 노출되고 메트릭을 노출시키는지 보여주는 캡처입니다.

exporter는 이런식으로 메트릭을 노출한다 이 데이터를 프로메테우스가 가져가는구나~
이렇게 이해하시면 됩니다.
위 Pushgateway는 exporter로 부터 데이터를 push받아주는 서버입니다.
역할은 임시 및 배치작업 즉, 수명이 짧은 서비스에 대한 메트릭을 가져오기위해 사용 합니다.
Prometheus는 Exporter를 통해 다양한 서비스와 시스템에 대한 메트릭을 수집할 수 있도록 생태계가 구성되어있습니다. (참고)
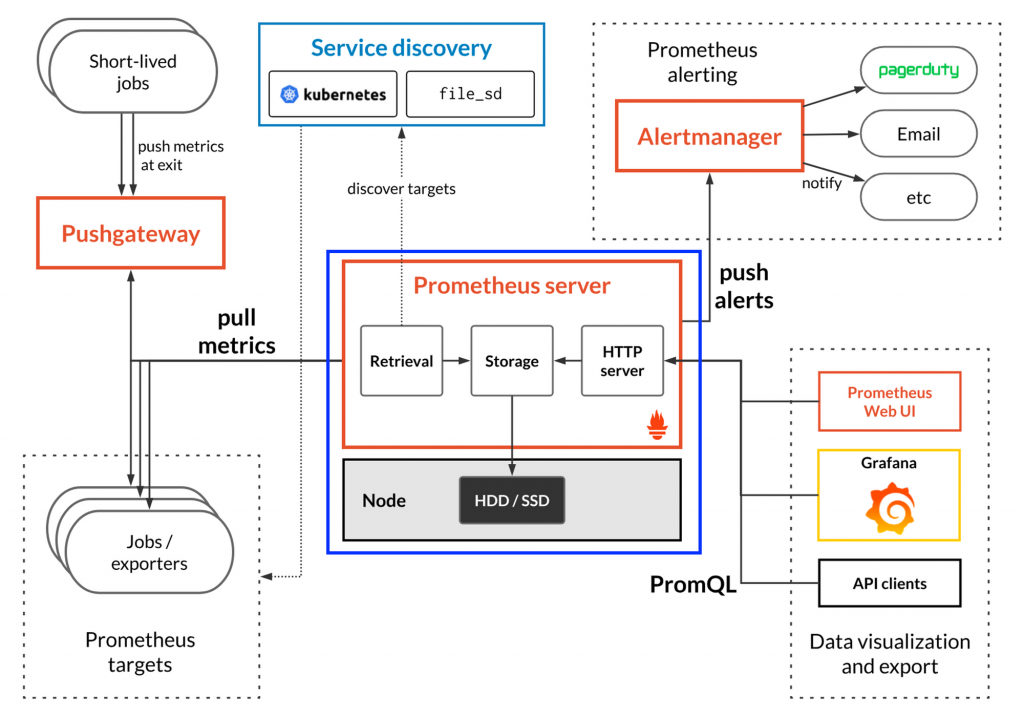
프로메테우스 서버는 메트릭 수집, 메트릭 저장, 알림전송, 데이터 노출 등 모니터링 서비스의 대부분을 차지하고 있습니다.
그 중 핵심이 되는것은 3가지 입니다.
Retrieval은 앞서 언급한 데이터 수집을 총괄하는 역할을 합니다.
Storage는 Local Storage(default)와 Remote Storage를 사용가능합니다.
저장되는 파일은 TSDB (Time Series Database)형식을 따릅니다.
TSDB(시계열 데이터베이스)란 일정한 시간 동안 수집된 일련의 순차적으로 정해진 데이터 셋의 집합이라고 알고 계시면 될 것 같습니다.
TSDB의 특징으로는 시간에 관해 순서가 매겨져 있다는 점과, 연속한 관측치는 서로 상관관계를 갖고 있습니다.
모니터링 시스템에는 시간별로 데이터를 구분해야하는데 이는 그래프에 사용되거나 쿼리문을 통한 데이터 분석시 필요하기에 TSDB를 사용하게됩니다.
HTTP server에서는 프로메테우스 서버가 가지고있는 메트릭을 다른 시각화 또는 데이터 활용을위해 HTTP API로 메이터를 수집, 추가, 삭제를 하기위하여 존재합니다.모든 메트릭은 API와 쿼리문을 통해 컨트롤 가능합니다.또한 자체 UI 서비스를 HTTP server를 통해 메트릭 확인이나 서비스 연결상태 등등 다양한 서비스를 이용할 수 있습니다.
타겟이 많은 대규모 환경에서 각 Exporter들의 메트릭을 Scraping하는 프로메테우스 서버의 부하를 무시할 수 없습니다.
대규모 모니터링 환경에서의 프로메테우스 사용 시 고려사항은 3가지 입니다.
데이터 저장은 Remote Storage를 사용하여 어느정도 해소할 수는 있지만 가용성과 데이터 처리는 Prometheus Federation 기능을 사용하여 어느정도 해소할 수 있습니다.
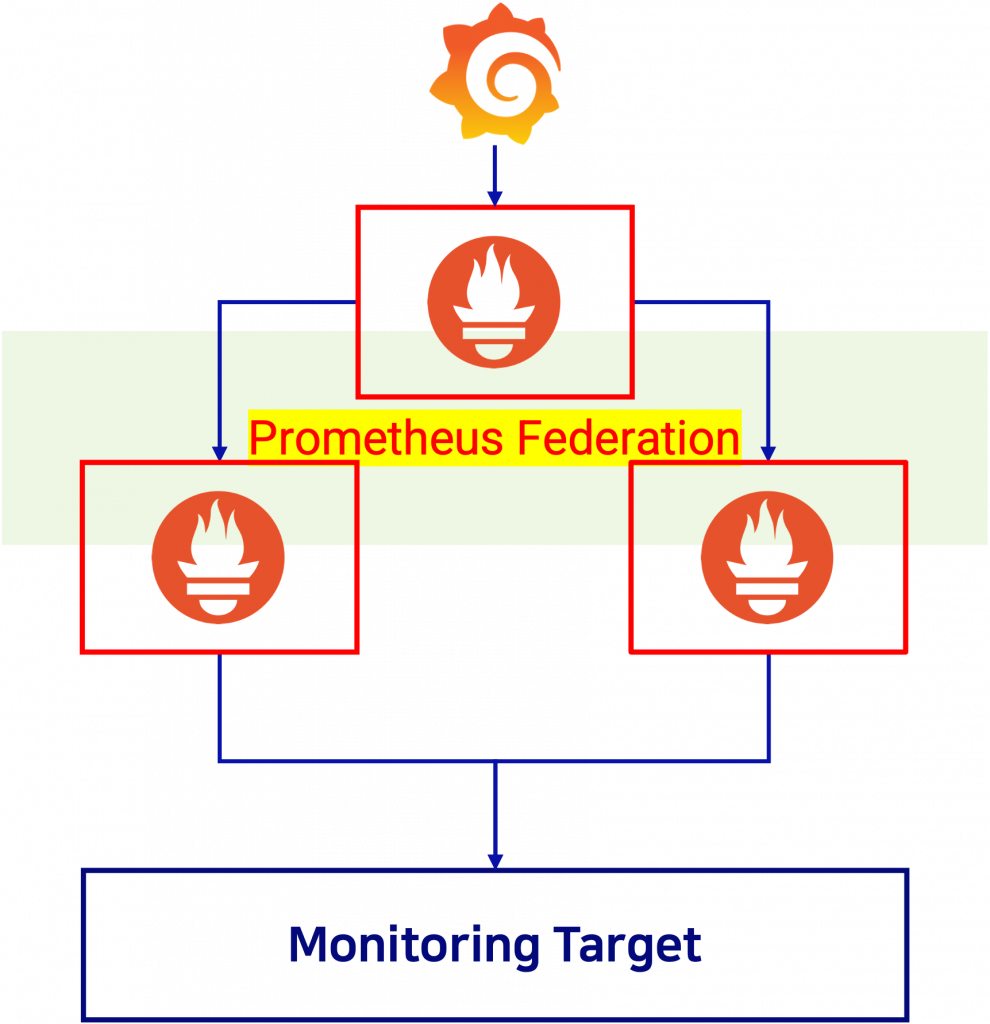
Prometheus Federation은 가용성을 위한 프로메테우스 기능입니다.
각각의 프로메테우스 서버가 타겟으로부터 메트릭을 가져오면 상단에 위치한 프로메테우스 서버가 데이터를 바라보게됩니다.최상단의 프로메테우스는 자기가 메트릭을 가지고있는 것처럼 보여집니다.
이런 구성을 한다면 타겟으로부터 데이터를 수집하는 프로메테우스 서버가 다운이 되어도 다른 서버에서 메트릭을 수집하기 때문에 데이터 수집 및 저장 단계에서 발생하는 장애포인트를 예방할 수 있습니다.
Prometheus Federation을 사용하다가 부하량이 감당이 안되면 Thanos나 Cortex같은 솔루션을 사용하여 대규모 분산 및 집계 중앙화 등 많은 방법을 통해 해소할 수 있습니다.
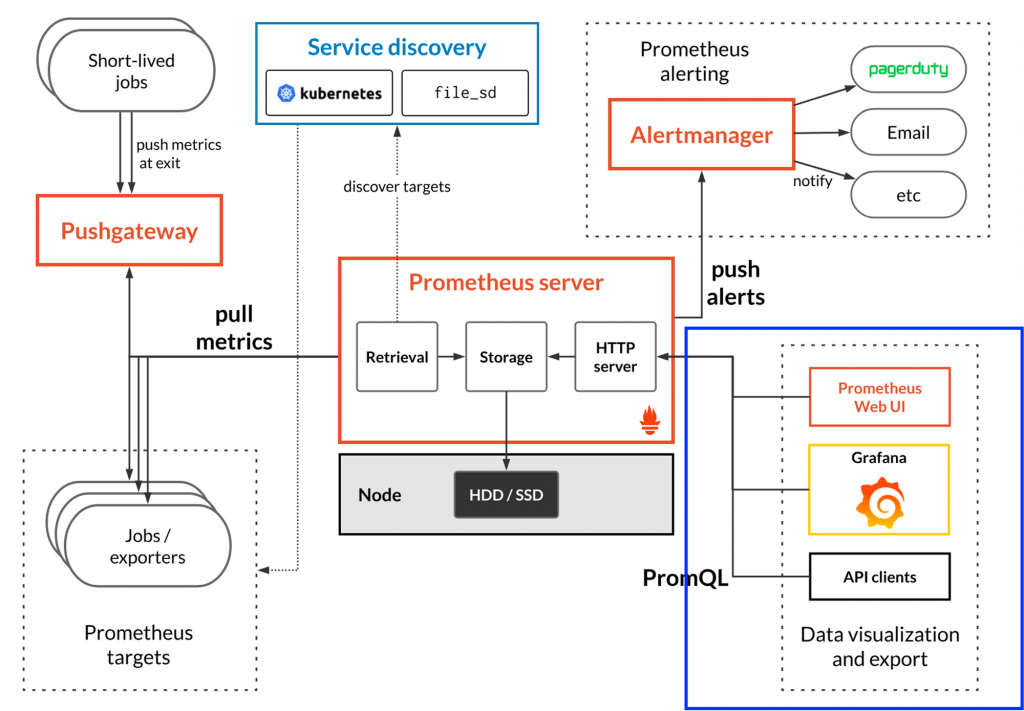
프로메테우스 서버로부터 데이터를 제공받아 사용하는 부분입니다.
데이터를 시각화 하거나 아까 말한 Prometheus Web UI를 통해 쿼리문을 테스트한다거나 Thrid-party client또는 Module을 사용하여 데이터 분석을 위해 사용할 수 있습니다.

Prometheus-Grafana 조합이 많은데 다른 조합 역시 많이 사용합니다.
push 기반 모니터링 서비스는 InfluexDB-Grafana, InfluxDB-Telegraf 조합을 많이 사용합니다.
Grafana는 모니터링 등 다양한 지표를 시각화 하는 대시보드 기능에 최적화된 제품입니다.
메트릭 값에 대한 임계치를 PromQL로 설정할 수 있습니다.
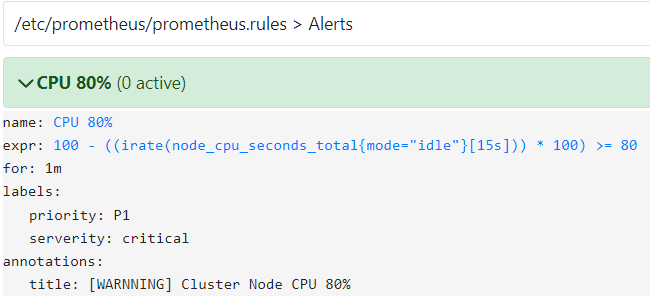
예를 들어
이런 임계값에대해 조건이 부합하면 알림을 보낼 수 있도록 설정할 수 있습니다.
이런 알림 처리는 Alertmanager에서 처리하게 됩니다.
Alertmanager는 Prometheus와 함께 작동하여 알림 및 경고 관리를 위한 도구입니다.
Prometheus는 시스템의 지표를 수집하고 모니터링하는 역할을 담당하며, Alertmanager는 이러한 지표를 기반으로 경고를 생성하고 관리합니다.
아래는 Alertmanager의 특징입니다.
결론부터 말씀드리자면 데이터 수집 방식 또는 선호도에 따라 제품 선택이 달라집니다.
Pull-Base = Prometheus / Push-Base = InfluxDB
두 가지 제품 모두 모니터링에 있어서 대표적으로 사용하는 제품입니다.
이 두 가지 모두 “태그-값” 데이터 모델을 사용하며 시계열 데이터를 관리하고 분석한다는 면에서 유사하지만 사용 방법에 따라 선호하는 제품이 달라지곤 합니다.
Prometheus와 InfluxDB의 차이점에 대해 간략히 설명 드리겠습니다.
앞서 말씀드렸다시피 Prometheus는 pull-based 방식을 사용합니다.
Prometheus 서버는 정기적으로 설정된 주기로 엔드포인트를 호출하여 데이터를 수집합니다.
데이터를 수집하려는 애플리케이션 또는 서비스는 Prometheus에 엔드포인트를 노출하여 Prometheus가 데이터를 가져오도록 허용합니다.
Prometheus는 또한 Pushgateway를 사용하여 Push-Base Monitoring 또한 가능합니다.
Pushgateway는 Prometheus가 pull-based 방식으로 수집할 수 없는 데이터 소스(예: 배치 작업, 짧은 지속 시간을 갖는 작업 등)에서 데이터를 수집하고자 할 때 사용됩니다.
InfluxDB는 기본적으로 push-based 방식을 사용합니다.
즉, 데이터를 생성하고 InfluxDB에 직접 전송하여 데이터를 저장합니다.
데이터를 생성하는 애플리케이션 또는 서비스는 InfluxDB에 데이터를 push하는 역할을 합니다.
InfluxDB는 내장된 HTTP API 또는 클라이언트 라이브러리를 사용하여 데이터를 전송합니다.
데이터를 생성한 후 HTTP POST 요청을 사용하여 InfluxDB에 데이터를 전송하고 저장합니다.
이러한 방식은 데이터 생성 소스가 데이터를 주체적으로 push하고 InfluxDB가 데이터를 수신하여 저장하는 push-based 방식입니다.
Pull-Base, Push-Base를 구분하는 것은 크게 의미가 없습니다.
Prometheus와 InfluxDB모두 Pull, Push 기반 수집이 가능하기 때문입니다.
하지만 일반적인 사용 용도에 따라 제품을 선택하게 되며 개발자 또는 엔지니어가 선호하는 방식에 따라 선택 되곤 합니다.
Prometheus는 PromQL, InfluxDB는 InfluxQL이라는 자체 쿼리 언어를 사용합니다.
Grafana 또는 Telegraf에서 각 제품의 쿼리문을 사용하여 대시보드를 설정하기에 수십 또는 수백 가지의 지표를 확인하기 위해 각각의 지표에 복잡한 쿼리문을 사용하게 됩니다.
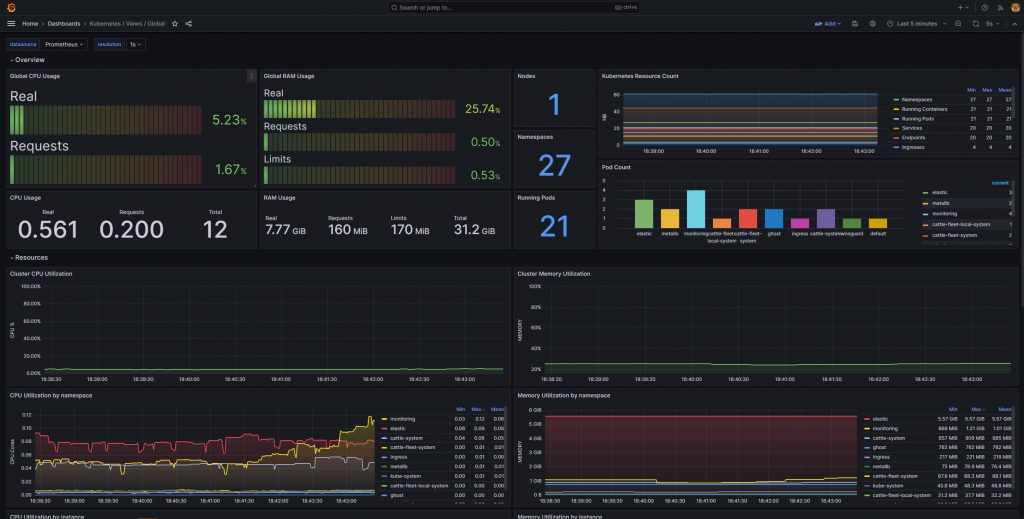
모니터링 관리자는 알림과 대시보드의 직접적인 연관이 있는 이 쿼리문을 읽고 쓰는데 능숙해야 합니다.
아래는 CPU 측정값 중 “cpu-total”과 일치하는 항목의 평균값을 가져오는 쿼리문을 제품별로 비교하는 예제입니다.
# InfluxQL
SELECT MEAN("usage_idle") AS "average_idle"
FROM "cpu"
WHERE "cpu" = 'cpu-total' AND time >= now() - 1h
GROUP BY time(10m)# PromQL
avg by(instance) (100 - avg by(instance)(irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
많은 기업에서 MSA(Micro Service Architecture) 기반으로 인프라를 설계하며 이제는 선택이 아닌 필수로 자리매김한 것 같네요.
24-365 모니터링 환경에서는 Atlassian OpsGenie의 Incoming call routing 기능을 활용한 착신 전화를 통해 장애 상황을 자동으로 전파하여 사용하기도 하니 참고해주시면 감사하겠습니다.