

안녕하세요. 오픈소스컨설팅 리눅스 엔지니어 김태현입니다.
다들 여름 더위는 잘 이겨내고 계신가요? 저는 요즘 리눅스 업무로 바쁜 나날을 보내고 있습니다.
최근에는 Pacemaker 교육 기회를 받아 수강했는데, 이를 통해 Pacemaker에 대한 흥미가 더 커졌답니다.
그래서 제가 이 주제를 다른 분들께도 공유하고 싶어서 글을 쓰게 되었습니다.
리눅스 운영체제를 사용하다 보면 시스템의 안정성과 가용성을 보장해야 하는 상황에 직면할 수 있습니다. 특히 중요한 서버 환경에서는 시스템의 다운타임이 기업의 이미지 등에 치명적인 영향을 끼칠 수 있고, 이런 상황에서는 Linux Pacemaker가 도움이 될 수 있습니다.
예를 들어, 데이터베이스(DB) 서버가 있습니다. 데이터베이스(DB) 서버는 많은 기업에서 아주 중요한 역할을 합니다. 데이터베이스(DB) 서버에 Pacemaker를 사용하여 클러스터를 구성하게된다면 데이터베이스 서비스의 안정성과 가용성을 높일 수 있습니다. 또한, Pacemaker를 통해 데이터베이스 인스턴스 간에 리소스 및 작업을 공유하며, 장애 상황에서 자동으로 다른 인스턴스로 전환하여 중단 없는 서비스를 제공할 수 있습니다.
이번 포스팅에서 Linux Pacemaker의 기능과 작동 원리를 알아보고, 어떻게 설치하고 구성 방법에 대해 알아보겠습니다. 기초적인 부분을 작성하였으니 처음 하시는 분들도 쉽게 따라하고 이해하실 수 있을겁니다.
고가용성(High-availability) 클러스터 리소스 관리자 소프트웨어입니다.
여러 대의 서버(노드)를 클러스터로 그룹화하고, 시스템의 가용성과 안정성을 높이기 위해 리소스 관리, 자동 장애 복구, 서비스 이동 등을 관리합니다.
간단히 말해, Pacemaker는 장애가 발생했을 때 서비스의 지속성을 보장하기 위해 여러 노드로 이뤄진 클러스터 시스템을 의미합니다. 이로 인해 하나의 서버에서 문제가 발생하더라도 다른 서버가 해당 역할을 대신하며 서비스를 중단시키지 않도록 합니다. 예를 들어 웹 서버, 데이터베이스, 파일 공유 등의 리소스가 클러스터 내에서 공유될 수 있습니다.
Pacemaker의 역사는 2003년 후반, SUSE의 Lars가 Heartbeat 프로젝트를 위해 새로운 CRM(클러스터 자원 관리자)을 개발하려는 아이디어로부터 시작되었습니다. CRM을 위해 Lars가 SUSE에게 Andrew Beekhof를 고용하도록 설득하였고, 그것이 Pacemaker 프로젝트의 출발이 되었습니다.
초기 Heartbeat는 클러스터 노드들 사이의 실시간 통신을 관리하며, 상태를 모니터링하고 장애가 발생했을 때 자동으로 작동을 전환하는 역할을 했습니다. 그러나 시간이 흐르면서 관리와 노드 간의 역할 조율이 더 복잡해지게 되었고, 더욱 강력하고 유연한 도구가 필요한 상황이었습니다. 이에 Pacemaker가 등장하게 되었습니다.
그러고 몇 년 후 2007년에 Andrew Beekhof가 리소스 감시 기능을 Pacemaker라는 새로운 제품으로 분리할 것이라고 발표했습니다. 이렇게 리소스 감시 기능이 더욱 강화된 Pacemaker는 Heartbeat와의 연결을 끊고 독립적으로 발전하게 되었습니다. 이런 발전으로 인해 2008년에는 Pacemaker 버전 1.0이 릴리스되었고, 현재 Pacemaker는 클러스터 관리와 고가용성 보장을 위한 필수적인 솔루션으로 자리잡게 되었습니다.
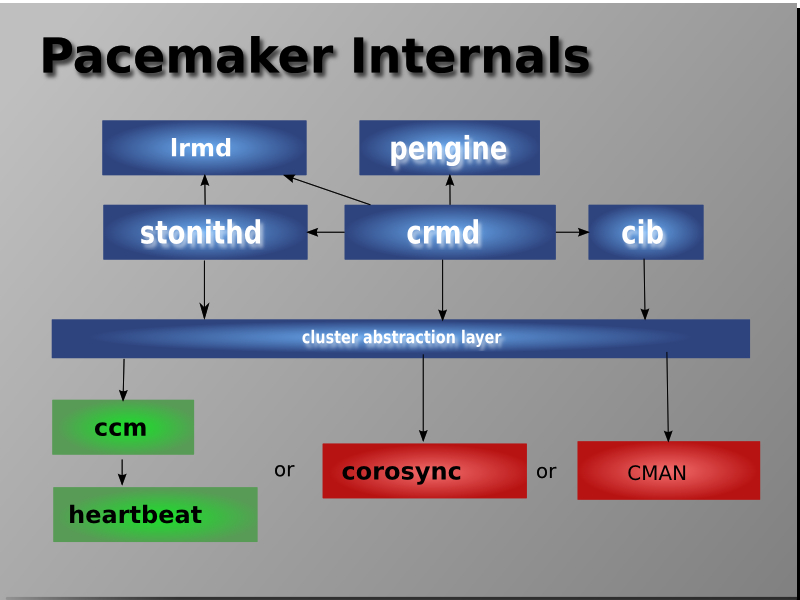
*split-brain : 클러스터에서 노드 간의 통신이 끊어져서 동일한 리소스 또는 서비스를 동시에 제어하려는 상태를 의미합니다.
Pacemaker는 Active/Active , Active/Passive , N+1 , N+M , N-to-1 및 N-to-N을 포함한 거의 모든 노드 중복 구성을 지원합니다 .
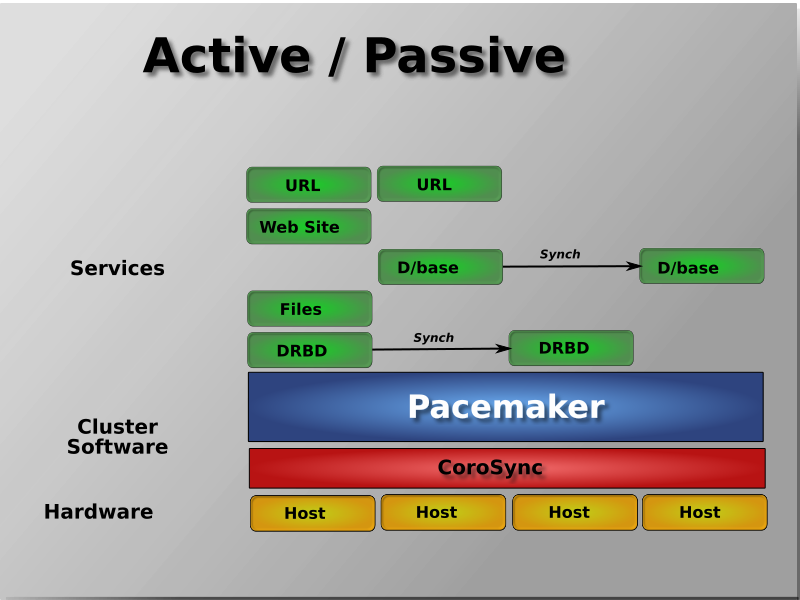
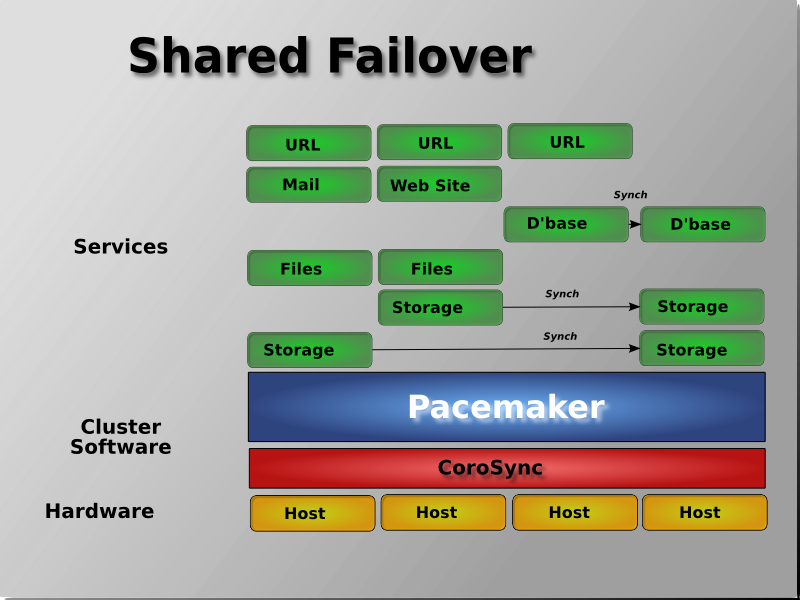
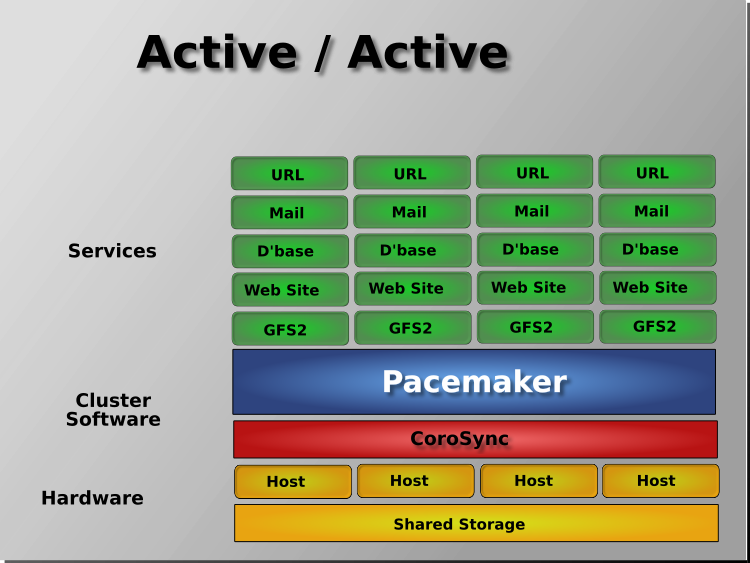
| RHEL | 7버전 이상부터 사용 가능 ( 6버전부터 가능하지만, 초기 버전이었기 때문에 최신 기능이나 보안 업데이트가 포함되지 않을 수 있습니다. 권고x) |
| CentOS | 7버전 이상부터 사용 가능 (RHEL과 동일함) |
| Ubuntu | 14.04버전 이상부터 사용 가능 |
| SUSE Linux | 11버전 이상부터 사용 가능 |

[root@node1 ~]# cat /etc/hosts
192.168.90.110 node1.example.com node1
192.168.90.120 node2.example.com node2
192.168.90.130 node3.example.com node3
192.168.90.140 node4.example.com node4[root@node1 ~]# dnf --enablerepo=highavailability -y install pacemaker pcs
[root@node1 ~]# rpm -qa | egrep "pacemaker|pcs|corosync"
corosynclib-3.1.7-1.el9.x86_64
corosync-3.1.7-1.el9.x86_64
pacemaker-schemas-2.1.6-6.el9.noarch
pacemaker-libs-2.1.6-6.el9.x86_64
pacemaker-cluster-libs-2.1.6-6.el9.x86_64
pacemaker-2.1.6-6.el9.x86_64
pacemaker-cli-2.1.6-6.el9.x86_64
pcs-0.11.6-3.el9.x86_64[root@node1 ~]# cat /etc/passwd | grep hacluster
hacluster:x:189:189:cluster user:/home/hacluster:/sbin/nologin
[root@node1 ~]# passwd hacluster
##모든 노드의 hacluster계정 패스워드는 동일해야됩니다.[root@node1 ~]# systemctl enable --now pcsd.service
Created symlink /etc/systemd/system/multi-user.target.wants/pcsd.service → /usr/lib/systemd/system/pcsd.service.
[root@node1 ~]# firewall-cmd --permanent --add-service=high-availability
[root@node1 ~]# firewall-cmd --reload[root@node1 ~]# pcs host auth node1.example.com node2.example.com node3.example.com node4.example.com
Username: hacluster
Password:
node1.example.com: Authorized
node2.example.com: Authorized
node3.example.com: Authorized
node4.example.com: Authorized
## hacluster와 패스워드를 넣어줍니다.[root@node1 ~]# pcs cluster setup ha_cluster_lab node1.example.com node2.example.com node3.example.com node4.example.com
Cluster has been successfully set up.
[root@node1 ~]# pcs cluster start --all
node3.example.com: Starting Cluster...
node2.example.com: Starting Cluster...
node4.example.com: Starting Cluster...
node1.example.com: Starting Cluster...[root@node1 ~]# pcs cluster status
Cluster Status:
Cluster Summary:
- Stack: corosync (Pacemaker is running)
- Current DC: [node2.example.com](http://node2.example.com/) (version 2.1.6-6.el9-6fdc9deea29) - partition with quorum
- Last updated: Tue Aug 1 13:59:06 2023 on [node1.example.com](http://node1.example.com/)
- Last change: Tue Aug 1 13:58:41 2023 by hacluster via crmd on [node2.example.com](http://node2.example.com/)
- 4 nodes configured
- 0 resource instances configured
Node List:
- Online: [ [node1.example.com](http://node1.example.com/) [node2.example.com](http://node2.example.com/) [node3.example.com](http://node3.example.com/) [node4.example.com](http://node4.example.com/) ]
PCSD Status:
[node4.example.com](http://node4.example.com/): Online
[node2.example.com](http://node2.example.com/): Online
[node1.example.com](http://node1.example.com/): Online
[node3.example.com](http://node3.example.com/): Online[root@node1 ~]# pcs status corosync
Membership information
----------------------
Nodeid Votes Name
1 1 node1.example.com (local)
2 1 node2.example.com
3 1 node3.example.com
4 1 node4.example.com
Pacemaker를 구성 후에 어떠한 이유로 노드 구성 변경이 필요할때가 생길수 있습니다. 어떻게 구성을 변경할 수 있을까요? Pacemaker에서는 pcs 명령을 통해 노드 삭제 및 추가 기능을 제공합니다. 직접 실습으로 진행해 보겠습니다.
우선 노드를 제거하는 실습입니다. 노드를 제거하는 방법은 쉽고 간단합니다.
1. 제거할 노드를 멈춰주시고 2. cluster 노드에서 삭제해주시면되겠습니다.
node4를 제거해보겠습니다.
[root@node1 ~]# pcs cluster stop node4.example.com
node4.example.com: Stopping Cluster (pacemaker)...
node4.example.com: Stopping Cluster (corosync)...
[root@node1 ~]# pcs cluster node delete node4.example.com
Destroying cluster on hosts: 'node4.example.com'...
node4.example.com: Successfully destroyed cluster
Sending updated corosync.conf to nodes...
node1.example.com: Succeeded
node2.example.com: Succeeded
node3.example.com: Succeeded
node1.example.com: Corosync configuration reloadednode4가 제거된 것을 확인 하실 수 있습니다.
[root@node1 ~]# pcs cluster status
Cluster Status:
Cluster Summary:
* Stack: corosync (Pacemaker is running)
* Current DC: node2.example.com (version 2.1.6-6.el9-6fdc9deea29) - partition with quorum
* Last updated: Tue Aug 1 14:51:48 2023 on node1.example.com
* Last change: Tue Aug 1 14:51:29 2023 by hacluster via crm_node on node2.example.com
* 3 nodes configured
* 0 resource instances configured
Node List:
* Online: [ node1.example.com node2.example.com node3.example.com ]
PCSD Status:
node2.example.com: Online
node3.example.com: Online
node1.example.com: Online
노드를 추가하는 방법은 기본 구성에서 진행했던 방법과 비슷합니다.
1.추가할 노드를 인증해주시고 2.노드를 추가해주시면 되겠습니다.
제거했던 node4를 추가해주겠습니다.
[root@node1 ~]# pcs host auth -u hacluster -p centos node4.example.com
node4.example.com: Authorized
[root@node1 ~]# pcs cluster node add node4.example.com --enable --start
No addresses specified for host 'node4.example.com', using 'node4.example.com'
Disabling sbd...
node4.example.com: sbd disabled
Sending 'corosync authkey', 'pacemaker authkey' to 'node4.example.com'
node4.example.com: successful distribution of the file 'corosync authkey'
node4.example.com: successful distribution of the file 'pacemaker authkey'
Sending updated corosync.conf to nodes...
node1.example.com: Succeeded
node2.example.com: Succeeded
node3.example.com: Succeeded
node4.example.com: Succeeded
node1.example.com: Corosync configuration reloaded
Enabling cluster on hosts: 'node4.example.com'...
node4.example.com: Cluster enabled
Starting cluster on hosts: 'node4.example.com'...node4가 추가된 것을 확인 하실 수 있습니다.
[root@node1 ~]# pcs cluster status
Cluster Status:
Cluster Summary:
* Stack: corosync (Pacemaker is running)
* Current DC: node2.example.com (version 2.1.6-6.el9-6fdc9deea29) - partition with quorum
* Last updated: Tue Aug 1 15:03:53 2023 on node1.example.com
* Last change: Tue Aug 1 15:03:40 2023 by hacluster via crmd on node2.example.com
* 4 nodes configured
* 0 resource instances configured
Node List:
* Online: [ node1.example.com node2.example.com node3.example.com node4.example.com ]
PCSD Status:
node1.example.com: Online
node3.example.com: Online
node4.example.com: Online
node2.example.com: Online
지금까지 Linux pacemaker에 관련한 기초적인 내용을 알아보았습니다.
가용성과 안정성은 현대 IT 환경에서 절대적으로 중요한 가치입니다. Linux Pacemaker가 높은 신뢰성과 안정성을 원하는 사람들에게 큰 도움이 될 것이라 생각합니다.
이 포스팅을 통해서 pacemaker의 기초 부분을 많은 분들이 더욱 더 쉽게 이해하셨으면 좋겠습니다.
다음 시간에는 구성된 클러스터환경에서 원하는 리소스를 다양하게 만들어 구성해보고, Stonith를 이용해 리소스들을 Fencing하는 방법을 알려드리겠습니다.
읽어주셔서 감사합니다.
[1]. ClusterLabs > Home