

안녕하세요. 오픈소스를 다루는 것을 좋아하는 Linux팀의 엔지니어 조철진이라고 합니다!
여러분들은 업무를 하면서 ChatGPT를 사용하시나요? ChatGPT는 OpenAI에서 GPT를 기반으로 개발된 대화형 인공지능 모델로, 업무를 하며 사용하다 보면 AI가 인간에게 도움을 줄 수 있다는 것을 체감하고 있습니다.
오늘 소개 드릴 소프트웨어는 OpenAI에서 개발한 또 다른 소프트웨어 Whisper 입니다.
Whisper 또한 GPT 기반으로 개발된 음성 인식 모델로 음성을 텍스트로 변환할 수 있는 소프트웨어입니다.
특히 놀라운 점은 정말 다양한 국적의 언어를 지원한다는 점인데요, 음성을 통해 텍스트를 생성해야 하는 작업이 필요하다면 무료이면서 효과적으로 이 소프트웨어를 활용할 수 있을 것으로 생각됩니다.
긴 이론 설명 필요 없이 바로 사용해보며 알아보겠습니다.
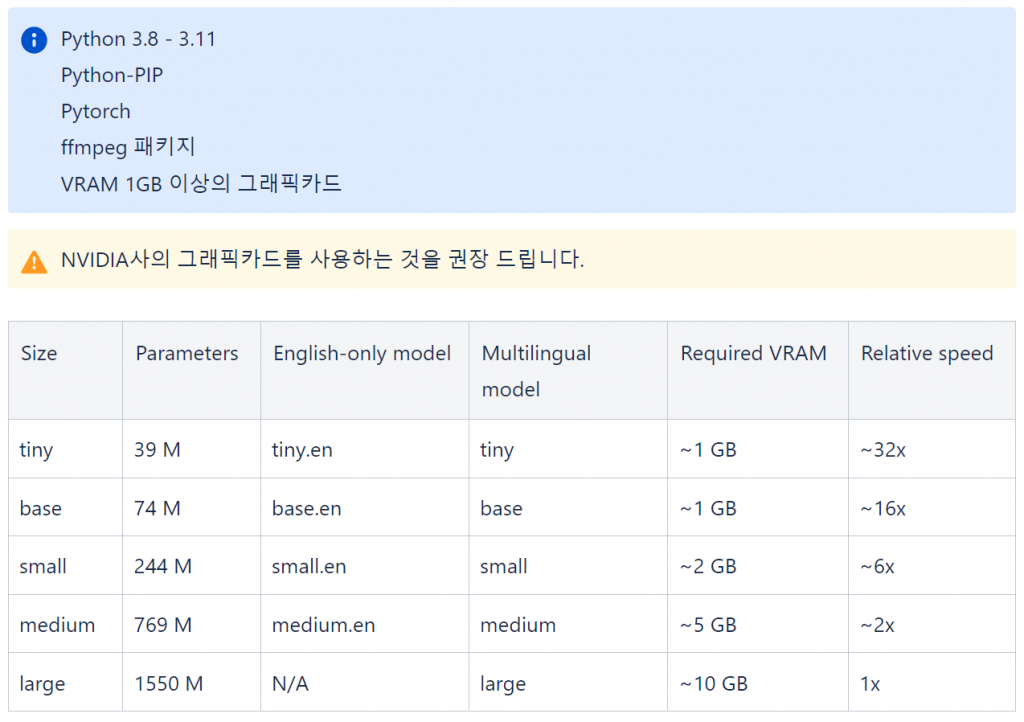
사용할 수 있는 Model 크기 별로 요구되는 그래픽카드의 VRAM이 다릅니다. 큰 Size의 모델을 사용할수록 정확한 텍스트 변환이 이루어지지만 더욱 많은 VRAM이 필요하고 처리 속도에 영향을 미칩니다.
다양한 OS 환경에서 사용할 수 있으며 자세한 사항은 공식 Github를 참고해주세요.
https://github.com/openai/whisper
저는 아래의 Windows 데스크톱 환경에서 준비해 보았습니다.

Set-ExecutionPolicy RemoteSigned -Scope CurrentUserirm get.scoop.sh | iex
scoop install pythonpip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu118python -c 'import torch; print(\"CUDA enabled:\", torch.cuda.is_available());'올바른 결과
CUDA enabled: Truepip install -U openai-whisperscoop install ffmpegpip install ffmpeg-python
본격적으로 Whisper를 사용해 보겠습니다. 변환 가능한 파일은 flac, mp3, wav 등의 오디오 파일 입니다.
만약, mp4와 같은 영상 파일은 mp3 파일로 먼저 변환이 필요합니다.
저는 뉴진스의 OMG 뮤직 비디오를 mp3 추출하여 준비해 보았습니다. 뉴진스의 노래들은 영어 비중이 굉장히 많아서 처음에 잘 들리지 않는 경향이 있어 샘플로 매우 적합해 보였습니다.
첫 실행 시 모델의 다운로드를 진행하여 시간이 소요될 수 있으며, 오디오 파일의 크기에 따라 소요될 수 있는 시간이 다릅니다. model의 크기를 지정하지 않는다면 small 모델이 선택됩니다.
whisper OMG.mp3 --language Korean --model medium해당 명령을 실행시키면 변환되는 텍스트가 영상의 시간과 함께 PowerShell에 출력 되고 명령이 끝나면 실행한 디렉토리 위치에 json, srt, tsv, vtt, txt 다양한 형식으로 텍스트가 변환 되어 저장됩니다.
원하는 형식만 저장하고 싶다면 아래와 같이 --output_format 옵션으로 지정해 사용가능 합니다.
whisper OMG.mp3 --language Korean --model medium --output_format txt실제 가사와 1절 까지만 비교를 해보겠습니다.
보기 쉽게 비교하기 위해 실제 가사에 맞춰 변환 결과에 줄 바꿈을 많이 사용한 점 참고 부탁 드립니다.

완벽하지는 않지만, 영어는 영어로 변환해주면서 한글은 한글로 준수하게 변환한 결과가 확인 됩니다.
Whisper는 --initial_prompt 옵션을 지원하여 아래와 같이 변환하는 오디오의 목적이나 오디오에서 사용하는 고유명사를 알려주면 더욱 사용자가 원하는 정확한 형태로 변환이 가능합니다.
이 부분은 여러분이 원하는 오디오를 자유롭게 테스트 해보시면 좋을 것 같습니다.
whisper OMG.mp3 --language Korean --model medium --output_format txt --initial_prompt "이 노래는 KPOP 그룹 뉴진스의 노래야."앞선 소개에서 Whisper는 다양한 국적의 언어를 지원한다고 말씀드렸는데요.
110개 언어가 지원되는 것으로 확인되어 정말 다양한 데이터를 학습한 모델이라고 볼 수 있겠습니다.
Whisper 지원 언어
Afrikaans, Albanian, Amharic, Arabic, Armenian, Assamese, Azerbaijani, Bashkir, Basque, Belarusian, Bengali, Bosnian, Breton, Bulgarian, Burmese, Castilian, Catalan, Chinese, Croatian, Czech, Danish, Dutch, English, Estonian, Faroese, Finnish, Flemish, French, Galician, Georgian, German, Greek, Gujarati, Haitian, Haitian Creole, Hausa, Hawaiian, Hebrew, Hindi, Hungarian, Icelandic, Indonesian, Italian, Japanese, Javanese, Kannada, Kazakh, Khmer, Korean, Lao, Latin, Latvian, Letzeburgesch, Lingala, Lithuanian, Luxembourgish, Macedonian, Malagasy, Malay, Malayalam, Maltese, Maori, Marathi, Moldavian, Moldovan, Mongolian, Myanmar, Nepali, Norwegian, Nynorsk, Occitan, Panjabi, Pashto, Persian, Polish, Portuguese, Punjabi, Pushto, Romanian, Russian, Sanskrit, Serbian, Shona, Sindhi, Sinhala, Sinhalese, Slovak, Slovenian, Somali, Spanish, Sundanese, Swahili, Swedish, Tagalog, Tajik, Tamil, Tatar, Telugu, Thai, Tibetan, Turkish, Turkmen, Ukrainian, Urdu, Uzbek, Valencian, Vietnamese, Welsh, Yiddish, Yoruba
Whisper의 공식 Github에 게시된 언어 별 단어 인식률 순위 차트입니다.
이렇게 다양한 국가의 데이터를 학습한 Whisper는 --task translate 옵션을 통해 지원하는 모든 국가의 언어를 영어로 번역이 가능합니다. 아쉽게도 영어가 아닌 언어로의 번역은 “공식적으로” 지원하지 않습니다.
하지만, 번역기의 도움을 받으면 이러한 아쉬움도 손쉽게 충족이 가능한 시대이죠.
이번에는 JPOP 가수 아이묭의 Marigold 뮤직비디오를 예시로 준비해 보았습니다.
항상 노래가 좋아서 들으면서도 가사의 의미는 전혀 몰랐는데, 이번 기회에 한번 알아보게 되었네요.
whisper Marigold.mp3 --language Japanese --model medium --output_format txt --task translate
번역기의 번역이므로 어색한 부분이 있지만, 의미는 파악 가능한 수준입니다.
공식 문서 상으로 번역은 영어만 지원하지만 아래와 같이 다른 언어의 오디오를 입력하면서 번역하기를 원하는 언어를 --language 옵션을 통해 지정하면 번역이 가능하긴 합니다. [3]
하지만 번역 프로그램이 아니다 보니 번역 품질이 별로 좋지 않음을 알 수 있었습니다.
whisper Marigold.mp3 --language Korean --model medium --output_format txt지금까지 OpenAI의 음성 인식 모델 Whisper를 살펴보았습니다.
제가 가볍게 다뤄본 명령 줄 프로그램 외에도 본 프로젝트는 오픈소스로 만들어져 Python 라이브러리로 원하는 대로 코드를 작성하여 사용하는 것도 가능합니다.
저는 개인적으로 AI 기술의 발전이 별로 체감 되지 않았던 사람인데 ChatGPT와 Whisper를 사용해보면서 완벽하지는 않지만 누구나 쉽게 AI를 접할 수 있는 시대가 되었음을 실감하고 있습니다.
앞으로의 발전이 정말 기대되며 추후에도 재미있는 소식을 전할 수 있으면 좋겠습니다. 감사합니다!
[1] https://github.com/openai/whisper