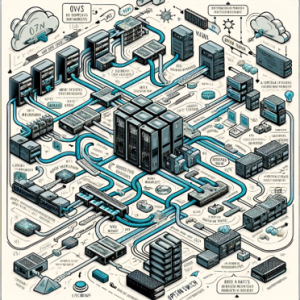
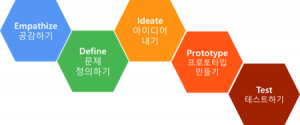
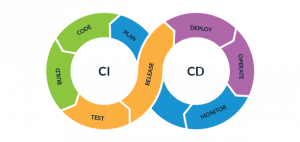
Agile AI Atlassian atlassian app bitbucket centos Cloud confluence container DevOps docker dockerimage form Front-End Frontend Javascript jira Kanban Kubernetes Linux marketplaceapp migration network Open Source OpenStack Playce Cloud Playce Kube PlayceRoRo React react-hook-form React.js Recoil Rocky Linux SAFe scriptrunner State Typescript Web Web-Frontend WebDevelop 도커 아틀라시안 애자일 오픈소스컨설팅 컨테이너