

ņĢłļģĢĒĢśņäĖņÜö. ņĀĆĒؼļŖö ņśżĒöłņåīņŖżņ╗©ņäżĒīģ ļ”¼ļłģņŖżĒīĆ ņ×ģļŗłļŗż. ņĀĆĒؼļŖö ļ”¼ļłģņŖż ļ░Å Ļ┤ĆļĀ© ņåöļŻ©ņģśņŚÉ ļīĆĒĢ┤ ĻĖ░ņłĀņ¦ĆņøÉņØä ĒĢśĻ│Ā ņ׳ņŖĄļŗłļŗż.
ņØ┤ļ▓ł ĻĖĆņŚÉņä£ļŖö ņä£ļ▓ä ļ¬©ļŗłĒä░ļ¦üņØä ņ£äĒĢ£ ņŚ¼ļ¤¼ Ēł┤ ņżæņŚÉņä£ļÅä ĻĖ░ļ│ĖņĀüņ£╝ļĪ£ ļ¦ÄņØ┤ ņé¼ņÜ®ĒĢśņŗ£ļŖö sarņŚÉ ļīĆĒĢ┤ ļŗżļżäļ│┤ļĀżĻ│Ā ĒĢ®ļŗłļŗż.
ļ”¼ļłģņŖż ņä£ļ▓äļź╝ ņÜ┤ņśüĒĢśļŗżļ│┤ļ®┤ ļ”¼ņåīņŖż ņé¼ņÜ®ļ¤ēņØä ĒÖĢņØĖĒĢ┤ņĢ╝ ĒĢĀ Ļ▓ĮņÜ░Ļ░Ć ņ׳ļŖöļŹ░ņÜö.
ņØ┤ļ¤¼ĒĢ£ Ļ▓ĮņÜ░ ļīĆļČĆļČäņØś ļ”¼ļłģņŖż ļ░░ĒżĒīÉņŚÉ ņäżņ╣śļÉśļŖö sar ļź╝ ĒÖ£ņÜ®ĒĢśļ®┤ ņä£ļ▓äņŚÉņä£ ņé¼ņÜ®ļÉśļŖö ņ×ÉņøÉņØś ņé¼ņÜ®ļ¤ēņØä ņĀĢĒÖĢĒĢśĻ▓ī ĒīīņĢģ ĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż.
sar ņÖĖņŚÉļÅä ļ¦ÄņØĆ ņ£ĀņÜ®ĒĢ£ ļÅäĻĄ¼ļōżņØ┤ ņ׳ņ¦Ćļ¦ī, sar ļŖö ņØ┤ļ»Ė ņäżņ╣śļÉśņ¢┤ ņ׳Ļ▒░ļéś ĻĖ░ļ│Ė ļ”¼Ēżņ¦ĆĒåĀļ”¼ņŚÉņä£ Ļ░ĆņĀĖņś¼ ņłś ņ׳ņ¢┤ņä£ ļČäņäØņØä ļ╣Āļź┤Ļ▓ī ņŗ£ņ×æĒĢĀ ņłś ņ׳ļŗżļŖö ņןņĀÉņØ┤ ņ׳ņŖĄļŗłļŗż.
sar ļŖö system activity report ļ¬ģļĀ╣ ļÅäĻĄ¼ņ×ģļŗłļŗż. Ēśäņ×¼ ņé¼ņÜ®ļ¤ē ļ┐É ņĢäļŗłļØ╝, ņŗ£ņŖżĒģ£ņŚÉ ņśłņĢĮņ×æņŚģņ£╝ļĪ£ ļō▒ļĪØļÉśņ¢┤ ņ׳ņ¢┤ņä£ ļ”¼ņåīņŖż ņé¼ņÜ®ļ¤ēņØä ņØ╝ņĀĢ ņŻ╝ĻĖ░ļ¦łļŗż ĻĖ░ļĪØ/ņĀĆņןĒĢśņŚ¼ ņØ┤ņĀäņØś ņāüĒā£ņÖĆ ļ│ĆĒÖö ņČöņØ┤ļź╝ ĒÖĢņØĖĒĢĀ ņłś ņ׳ļŗżļŖö ņןņĀÉņØ┤ ņ׳ņŖĄļŗłļŗż.
ņØ╝ļ░śņĀüņ£╝ļĪ£ļŖö OS ņäżņ╣śĒĢśļ®┤ņä£ Ļ░ÖņØ┤ ņäżņ╣śļÉśļŖö Ļ▓ĮņÜ░Ļ░Ć ļ¦Äņ¦Ćļ¦ī, minimal ņłśņżĆņ£╝ļĪ£ ņäżņ╣śĒĢśņŗż Ļ▓ĮņÜ░ ņäżņ╣śĻ░Ć ļÉśņ¢┤ ņ׳ņ¦Ć ņĢŖņØä ņłś ņ׳ņŖĄļŗłļŗż.
ĻĘĖļ¤░ Ļ▓ĮņÜ░ņŚÉļŖö ļŗ╣ĒÖ®ĒĢśņ¦Ć ļ¦łņŗ£Ļ│Ā sysstat ņØ┤ļØ╝ļŖö Ēī©Ēéżļ¦ī ņäżņ╣śĒĢ┤ ņŻ╝ņŗ£ļ®┤ ļ░öļĪ£ ņé¼ņÜ®ņØ┤ Ļ░ĆļŖźĒĢśļŗł ņØ┤ņĀÉ Ļ╝Ł ĻĖ░ņ¢ĄĒĢśņŗ£ĻĖ░ ļ░öļ׏ļŗłļŗż.
sarļź╝ ņé¼ņÜ®ĒĢĀ ļĢī ņŚ¼ļ¤¼ optionņØä ņŻ╝ņ¢┤ņä£ ļŗżņ¢æĒĢ£ ņĀĢļ│┤ļź╝ ĒÖĢņØĖ ĒĢĀ ņłś ņ׳ļŖöļŹ░ņÜö.
ņŗżņĀ£ ņØ┤ņŖł ņ╝ĆņØ┤ņŖżņŚÉ ļö░ļØ╝ ņ¢┤ļ¢ż fieldļź╝ ĒÖĢņØĖĒĢśĻ│Ā ļČäņäØĒĢĀ ņłś ņ׳ļŖöņ¦Ć ņĢīņĢäļ│┤ļÅäļĪØ ĒĢśĻ▓ĀņŖĄļŗłļŗż.
Memory 100% , Reboot
ņØ┤ ņé¼ļĪĆļŖö ņŗ£ņŖżĒģ£ņØ┤ ļ®öļ¬©ļ”¼ļź╝ 100% ņé¼ņÜ® ĒĢ£ Ēøä reboot ļÉ£ ņāüĒÖ®ņØ┤Ļ│Ā,
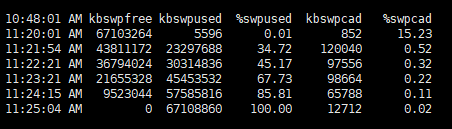
sar ļŹ░ņØ┤ĒāĆļź╝ ĒåĄĒĢ┤ ļČĆĒĢśņØś ņøÉņØĖ ļČäņäØņØä ņ¦äĒ¢ē ĒĢśņśĆņŖĄļŗłļŗż.
sar ļŹ░ņØ┤ĒāĆļŖö 11:25:04 AMņØä ļ¦łņ¦Ćļ¦ēņ£╝ļĪ£ ļŹö ņØ┤ņāü ņ░ŹĒ׳ņ¦Ć ņĢŖņĢśĻ│Ā, ņØ┤Ēøä ņŗ£ņŖżĒģ£ņØĆ ļ”¼ļČĆĒīģ ļÉśņŚłņŖĄļŗłļŗż.
ņ░ĖĻ│ĀļĪ£, ņØ┤ ņé¼ļĪĆņŚÉņä£ sar ļŖö 1ļČä ļŗ©ņ£äļĪ£ ņłśņ¦æ ļÉśņŚłņŖĄļŗłļŗż.
ņØ┤ ņŗ£ņŖżĒģ£ņØś OSļŖö RHEL7 ņ×ģļŗłļŗż.
ņÜ░ņäĀ sar ņØś ļ®öļ¬©ļ”¼ ņĀĢļ│┤ļź╝ ĒÖĢņØĖĒĢ┤ ļ│┤Ļ▓ĀņŖĄļŗłļŗż.
ļ®öļ¬©ļ”¼ ņĀĢļ│┤ļź╝ ĒÖĢņØĖĒĢśļŖö ņŚ¼ļ¤¼ ņśĄņģś ņżæņŚÉņä£ ņØ╝ļŗ© -r ņśĄņģśņØä ĒåĄĒĢ┤ņä£, ĒÖĢņØĖĒĢ┤ ļ│┤Ļ▓ĀņŖĄļŗłļŗż.

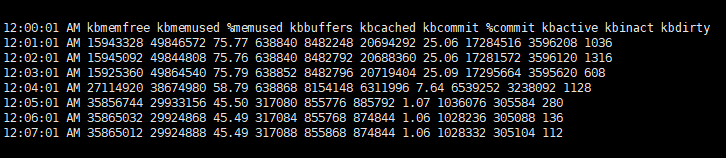
kbactive ņÖĆ %memused ņ×ģļŗłļŗż. ĒĢäļō£ļź╝ ņäżļ¬ģĒĢśļ®┤,
kbactive : ĒöäļĪ£ņäĖņŖżņŚÉ ņØśĒĢ┤ņä£, ļ╣äĻĄÉņĀü ņĄ£ĻĘ╝ņŚÉ ļ®öļ¬©ļ”¼ļĪ£ ļĪ£ļō£ļÉ£ ļ®öļ¬©ļ”¼ Ļ│ĄĻ░äņØś Ēü¼ĻĖ░ļź╝ ņØśļ»ĖĒĢśļ®░, kilobyte ļŗ©ņ£äņØś Ēæ£ņŗ£ņ×ģļŗłļŗż. ņĄ£ĻĘ╝ņŚÉ ļĪ£ļō£ļÉ£ ļ®öļ¬©ļ”¼ļŖö ĒöäļĪ£ņäĖņŖżņŚÉņä£ ņé¼ņÜ®ĒĢśļŖö ļČĆļČäņØ╝ ņłś ņ׳ņ£╝ļ»ĆļĪ£, ļŗżļźĖ ĒöäļĪ£ņäĖņŖżņØś ļ®öļ¬©ļ”¼ ņÜöņ▓Łņŗ£ņŚÉļÅä ļÉśļÅäļĪØņØ┤ļ®┤ ņØ┤ ņśüņŚŁņŚÉņä£ļŖö ņל ĒÜīņłśļÉśņ¦Ć ņĢŖņŖĄļŗłļŗż.%memused : Ēśäņ×¼ ņŗ£ņŖżĒģ£ņØś ņĀäņ▓┤ ļ®öļ¬©ļ”¼ ņżæņŚÉ ņé¼ņÜ®ņżæņØĖ ļ®öļ¬©ļ”¼ņØś ļ╣äņ£©ņØä Ēæ£ņŗ£ĒĢ®ļŗłļŗż.ņČöĻ░ĆņĀüņØĖ ļ®öļ¬©ļ”¼ ļČäņäØņØä ņ£äĒĢ┤, -B ņśĄņģśņØä ĒåĄĒĢ┤ņä£ page ņé¼ņÜ® ņĀĢļ│┤ļź╝ ĒÖĢņØĖĒĢ┤ ļ│┤Ļ▓ĀņŖĄļŗłļŗż.

pgpgin/s : ņ┤łļŗ╣ ņŗ£ņŖżĒģ£ņØ┤ ļööņŖżĒü¼ņŚÉņä£ ĒÄśņØ┤ņ¦ĢĒĢ£ ņ┤Ø Ēé¼ļĪ£ļ░öņØ┤ĒŖĖ ņłśņ×ģļŗłļŗż.pgpgout/s : ņ┤łļŗ╣ ņŗ£ņŖżĒģ£ņØ┤ ļööņŖżĒü¼ļĪ£ ĒÄśņØ┤ņ¦Ģ ņĢäņøāĒĢ£ ņ┤Ø Ēé¼ļĪ£ļ░öņØ┤ĒŖĖ ņłśņ×ģļŗłļŗż.pgfree/s : ņ┤łļŗ╣ ņŗ£ņŖżĒģ£ņŚÉņä£ ņé¼ņÜ® Ļ░ĆļŖźĒĢ£ ļ¬®ļĪØņŚÉ ļ░░ņ╣śĒĢ£ ĒÄśņØ┤ņ¦Ć ņłśņ×ģļŗłļŗż.pgscank/s : kswapd ļŹ░ļ¬¼ņØ┤ ņ┤łļŗ╣ ņŖżņ║öĒĢ£ ĒÄśņØ┤ņ¦Ć ņłśņ×ģļŗłļŗż.pgscand/s : ņ┤łļŗ╣ ņ¦üņĀæ ņŖżņ║öĒĢ£ ĒÄśņØ┤ņ¦Ć ņłśņ×ģļŗłļŗżpgsteal/s : ļ®öļ¬©ļ”¼ ņÜöĻĄ¼ļź╝ ņČ®ņĪ▒ĒĢśĻĖ░ ņ£äĒĢ┤ ņŗ£ņŖżĒģ£ņØ┤ ņ┤łļŗ╣ ņ║Éņŗ£(ĒÄśņØ┤ņ¦Ć ņ║Éņŗ£ ļ░Å ņŖżņÖæ ņ║Éņŗ£)ņŚÉņä£ ņ×¼ĒÖĢļ│┤ĒĢ£ ĒÄśņØ┤ņ¦Ć ņłśņ×ģļŗłļŗż.%vmeff : pgsteal / pgscanņ£╝ļĪ£ Ļ│äņé░ļÉśļŖö ņØ┤Ļ▓āņØĆ ĒÄśņØ┤ņ¦Ć ĒÜīņłś ĒÜ©ņ£©ņä▒ņØś ņ¦ĆĒæ£ņ×ģļŗłļŗż.pgpgin/s ņÖĆ pgpgout/s Ļ░Ć Ēü¼Ļ▓ī ņ”ØĻ░ĆĒĢ£ Ļ▓āņØä ļ│┤ņĢä ļööņŖżĒü¼ļź╝ ņØĮĻ│Ā ņō░ļŖö ņ×æņŚģņØ┤ ļŗżļ¤ē ļ░£ņāØĒĢ£ Ļ▓āņØä ņĢī ņłś ņ׳ņŖĄļŗłļŗż. ņ£äņØś sar -r ņŚÉņä£ Ļ░ÖņØĆ ņŗ£ņĀÉņŚÉ kbactive Ļ░Æņ▓śļ¤╝ ļ®öļ¬©ļ”¼Ļ░Ć ĻĖēņ”ØĒĢśĻ│Ā page in/out ņ£╝ļĪ£ ļ®öļ¬©ļ”¼ņÖĆ ļööņŖżĒü¼Ļ░äņØś I/O Ļ░Ć ļ¦ÄņØ┤ ņØ╝ņ¢┤ļé£ Ļ▓āņ£╝ļĪ£ ļ│┤ņ×ģļŗłļŗż.%vmeff ļŖö 24.03%ņØä ĻĖ░ļĪØĒĢśņśĆņŖĄļŗłļŗż. %vmeff ļŖö pgsteal (ĒÄśņØ┤ņ¦Ć ņ×¼ņé¼ņÜ®) / pgscan (ĒÄśņØ┤ņ¦Ć ņŖżņ║ö) ņØś ļ╣äņ£©ņØ┤ļ®░, ĒÄśņØ┤ņ¦Ć ņ×¼ņé¼ņÜ® ĒÜ©ņ£©ņØä ļ░▒ļČäņ£©ļĪ£ ļ│┤ņŚ¼ņżŹļŗłļŗż.%vmeff ļź╝ ĒåĄĒĢ┤ņä£ ĒöäļĪ£ņäĖņŖżņØś ļ®öļ¬©ļ”¼ ņÜöņ▓Łņ£╝ļĪ£ ĒĢäņÜöĒĢ£ ļ¦īĒü╝ ļ®öļ¬©ļ”¼ļź╝ ĒÜīņłśĒ¢łļŖöņ¦Ćļź╝ ņĢī ņłś ņ׳ņŖĄļŗłļŗż. ļ¬©ļōĀ ĒÄśņØ┤ņ¦Ćļź╝ ĒÜīņłśĒĢśļŖö ņāüĒā£ļŖö 100%ņØ┤ļ®░, ĒÄśņØ┤ņ¦Ć ņŖżņ║öņØ┤ ņŚåļŖö Ļ▓ĮņÜ░ņŚÉļŖö 0% ņ£╝ļĪ£ Ēæ£ņŗ£ļÉ®ļŗłļŗż. ņØ┤ Ļ░ÆņØĆ 0% ņØ┤Ļ▒░ļéś 100% ņŚÉ Ļ░ĆĻ╣īņøīņĢ╝ ņĀĢņāüņ×ģļŗłļŗż. ļ¦īņĢĮ 100%ļ│┤ļŗż ļé«ņØĆ ņłśņ╣śĻ░Ć ņ׳ņØä Ļ▓ĮņÜ░ņŚÉļŖö ļ®öļ¬©ļ”¼ ĒĢĀļŗ╣ ņÜöņ▓ŁņØä ĒĢśņśĆņ£╝ļéś, ņøÉĒĢśļŖö ņŗ£Ļ░ä ļé┤ņŚÉ ņ▓śļ”¼ ļÉśņ¦Ć ņĢŖņĢśņØä Ļ░ĆļŖźņä▒ņØ┤ ņ׳ņŖĄļŗłļŗż.ļ®öļ¬©ļ”¼Ļ░Ć ļČĆņĪ▒ĒĢ£ ņāüĒÖ®ņŚÉņä£ņØś, ļööņŖżĒü¼ I/O ļØ╝ļ®┤ swap In/Out ņØ┤ ļ░£ņāØĒ¢łņØä ņłśļÅä ņ׳ņŖĄļŗłļŗż.-S ņśĄņģśņØä ĒåĄĒĢ┤ņä£, swap Ļ│ĄĻ░äņØś ņé¼ņÜ®ļ¤ēņØä ĒÖĢņØĖĒĢ┤ ļ│┤Ļ▓ĀņŖĄļŗłļŗż.
%swpused ņ×ģļŗłļŗż.
%swpused : ņé¼ņÜ®ņżæņØĖ swap ļ®öļ¬©ļ”¼ Ēü¼ĻĖ░ņØ┤ņĀ£ CPU ļČĆĒĢśņÖĆ run queueļź╝ ĒÖĢņØĖĒĢ┤ļ│┤Ļ▓ĀņŖĄļŗłļŗż.
-u ņśĄņģśņ£╝ļĪ£ CPU ļČĆĒĢśļź╝ ĒÖĢņØĖĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż.
%iowait ņ×ģļŗłļŗż.%iowait : ĒöäļĪ£ņäĖņŖżĻ░Ć ļööņŖżĒü¼ I/O ņÜöņ▓Łņ£╝ļĪ£ ļīĆĻĖ░ ņāüĒā£ņŚÉ ņ׳ņŚłļŹś ņŗ£Ļ░äņØś ļ░▒ļČäņ£©sar -BņŚÉņä£ļÅä ļööņŖżĒü¼ I/OĻ░Ć ļ¦ÄņØ┤ ļ░£ņāØĒ¢łļŗżļŖö Ļ▓āņØä ĒÖĢņØĖĒĢśņśĆņ¦Ćļ¦ī sar -u ļĪ£ļÅä ĒöäļĪ£ņäĖņŖżņØś I/O ņÜöņ▓ŁņØ┤ ļ¦ÄņĢśļŗżļŖö Ļ▓āņØä ĒÖĢņØĖĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż. -q ņśĄņģśņ£╝ļĪ£ ĒüÉ(run queue) ĻĖĖņØ┤ņÖĆ Load Averagesļź╝ ĒÖĢņØĖĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż.
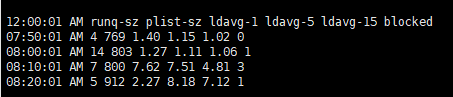
runq-szņÖĆ blocked ņ×ģļŗłļŗż.
runq-sz : ļ¤░ĒāĆņ×äņŚÉ ņŗżĒ¢ēļÉśĻĖ░ ņ£äĒĢ┤ ļīĆĻĖ░ ņżæņØĖ ĒöäļĪ£ņäĖņŖż ņłśblocked : I/O ņÜöņ▓ŁņØ┤ ņÖäļŻīļÉśĻĖ░ļź╝ ĻĖ░ļŗżļ”¼ļŖö ĒöäļĪ£ņäĖņŖż ņłś| sar ņØś -r , -B ņśĄņģśņØä ĒåĄĒĢ┤ņä£ memory usage ņÖĆ process ņØś memory ņÜöņ▓ŁņØ┤ ĻĖēņ”ØĒĢ£ Ļ▓āņØä ĒÖĢņØĖĒĢśņśĆņŖĄļŗłļŗż.ĻĘĖļ”¼Ļ│Ā, sar -S ļĪ£ memory Ļ░Ć ļČĆņĪ▒ņ£╝ļĪ£ ņØĖĒĢ£ swap used ņ”ØĻ░Ćļź╝ ĒÖĢņØĖĒ¢łņŖĄļŗłļŗż.ĻĘĖ ņØ┤ĒøäņŚÉļŖö sar ņĀĢļ│┤ļéś kernel dump ļō▒ņØ┤ ļ░£ņāØĒĢśņ¦ĆļŖö ļ¬╗ĒĢśņśĆņ¦Ćļ¦ī, Ļ│äņåŹņĀüņØĖ memory ļČĆņĪ▒ņØ┤ process ņłśĒ¢ēņØ┤ļéś block I/O ļÅÖņ×æļō▒ņØś ņ¦ĆņŚ░ņØä ņ£Āļ░£ĒĢśĻ│Ā ĻĘĖļĪ£ ņØĖĒĢ┤ ņĀäņ▓┤ņĀüņØĖ ņŗ£ņŖżĒģ£ ļÅÖņ×æ ļ¼ĖņĀ£ļĪ£ kernel ņØ┤ ņŗ£ņŖżĒģ£ņØä reboot Ē¢łņØä Ļ▓āņ£╝ļĪ£ ņČöņĀĢĒĢĀ ņłś ņ׳ņØä Ļ▓ā Ļ░ÖņŖĄļŗłļŗż. |
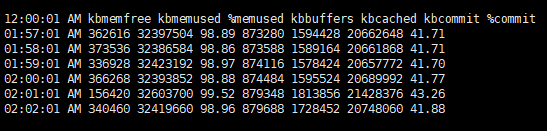
Memory Usage ņ”ØĻ░ĆņÖĆ Ļ░ÖņØĆ ņé¼ļĪĆļŖö ņŗ£ņŖżĒģ£ ļ®öļ¬©ļ”¼Ļ░Ć ņ”ØĻ░ĆļÉ£ ņøÉņØĖ ĒÖĢņØĖņØ┤ ĒĢäņÜöĒ¢łĻ│Ā, sar ļź╝ ĒåĄĒĢ┤ ļ®öļ¬©ļ”¼ ļ│ĆĒÖö ļō▒ņØä ĒåĄĒĢ┤ ņ¢┤ļ¢ĀĒĢ£ ĒŖ╣ņØ┤ņé¼ĒĢŁņØ┤ ņ׳ļŖöņ¦Ć ĒÖĢņØĖĒĢ┤ ļ│┤Ļ│Āņ×É ļČäņäØņØä ņ¦äĒ¢ēĒĢśņśĆņŖĄļŗłļŗż. ņ░ĖĻ│ĀļĪ£, ņØ┤ ņé¼ļĪĆņŚÉņä£ sar ļŖö 1ļČä ļŗ©ņ£äļĪ£ ņłśņ¦æļÉśņŚłņŖĄļŗłļŗż. ņØ┤ ņŗ£ņŖżĒģ£ņØś OSļŖö RHEL6 ņ×ģļŗłļŗż.
ļ®öļ¬©ļ”¼ ņĀĢļ│┤ļź╝ ĒÖĢņØĖĒĢśļŖö -r ņśĄņģśņØä ĒåĄĒĢ┤ņä£, ĒÖĢņØĖĒĢ┤ ļ│┤Ļ▓ĀņŖĄļŗłļŗż.
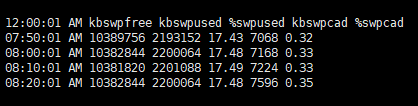
%memused ņ×ģļŗłļŗż. ĒĢäļō£ļź╝ ņäżļ¬ģĒĢśļ®┤,
%memused : Ēśäņ×¼ ņŗ£ņŖżĒģ£ņØś ņĀäņ▓┤ ļ®öļ¬©ļ”¼ ņżæņŚÉ ņé¼ņÜ®ņżæņØĖ ļ®öļ¬©ļ”¼ņØś ļ╣äņ£©ņØä Ēæ£ņŗ£ĒĢ®ļŗłļŗż.%memused ļŖö 98%~99%ņØś ņé¼ņÜ®ļźĀņØä ņ£Āņ¦ĆĒĢśĻ│Ā ņ׳ņŖĄļŗłļŗż.kbcachedņÖĆ kbbuffers ņØś Ļ░ÆņØĆ ĒĢ®ņ│Éņä£, 2~3GB ņĀĢļÅäļź╝ ņ░©ņ¦ĆĒĢśĻ│Ā ņ׳ņŖĄļŗłļŗż.kbcachedņÖĆ kbbuffersļź╝ ņĀ£ņÖĖĒĢśĻ│ĀļÅä, 30GB ņĀĢļÅäļĪ£ 90% ņØ┤ņāüņØś ļ®öļ¬©ļ”¼ļź╝ ņé¼ņÜ®ĒĢśļ»ĆļĪ£ ļ®öļ¬©ļ”¼ ņé¼ņÜ®ļ¤ēņØ┤ ļåÆļŗżĻ│Ā ļ│╝ ņ׳ņŖĄļŗłļŗż.ļ®öļ¬©ļ”¼ ņé¼ņÜ®ļźĀņØ┤ ļåÆņ£╝ļ»ĆļĪ£, Ēś╣ņŗ£ļéś swap ņśüņŚŁņØä ņé¼ņÜ®ĒĢśļŖöņ¦Ć ĒÖĢņØĖĒĢ┤ ļ│┤Ļ▓ĀņŖĄļŗłļŗż.-S ņśĄņģśņØä ĒåĄĒĢ┤ņä£, swap Ļ│ĄĻ░äņØś ņé¼ņÜ®ļ¤ēņØä ĒÖĢņØĖĒĢ┤ ļ│┤Ļ▓ĀņŖĄļŗłļŗż.
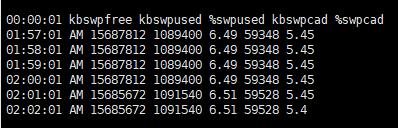
%swpused ņ×ģļŗłļŗż.
%swpused : ņé¼ņÜ®ņżæņØĖ swap ļ®öļ¬©ļ”¼ Ēü¼ĻĖ░%swpusedņØś ļ│ĆĒÖöĻ░Ć Ēü¼ņ¦Ć ņĢŖņŖĄļŗłļŗż.ņ£äņŚÉņä£ņØś -r ņśĄņģśņØä ĒåĄĒĢ£ ļé┤ņÜ®ņØĆ Ēśäņ×¼ ļ®öļ¬©ļ”¼Ļ░Ć ņ░©ņ¦ĆĒĢśĻ│Ā ņ׳ļŖö ņĀĢļÅäļ¦īņØä Ēæ£ņŗ£ĒĢśļ»ĆļĪ£, ņŗżņĀ£ļĪ£ ļ®öļ¬©ļ”¼ņŚÉņä£ņØś I/O Ļ░Ć ņ¢╝ļ¦łļéś ļ¦ÄņØ┤ ļ░£ņāØĒĢśļŖöņ¦ĆļŖö ĒÖĢņØĖņØ┤ ņ¢┤ļĀĄņŖĄļŗłļŗż.
ļ®öļ¬©ļ”¼ņŚÉņä£ņØś paging In/Out ņØä ĒÖĢņØĖĒĢśĻĖ░ ņ£äĒĢ┤, -B ņśĄņģśņØä ņé¼ņÜ®ĒĢ┤ņä£ ĒÖĢņØĖĒĢ┤ ļ│┤Ļ▓ĀņŖĄļŗłļŗż.
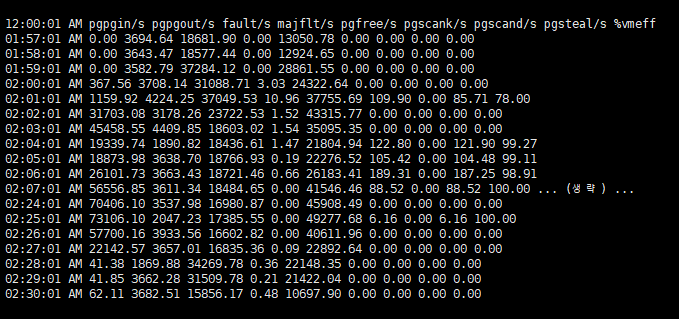
pgpgin/s : ņ┤łļŗ╣ ņŗ£ņŖżĒģ£ņØ┤ ļööņŖżĒü¼ņŚÉņä£ ĒÄśņØ┤ņ¦ĢĒĢ£ ņ┤Ø Ēé¼ļĪ£ļ░öņØ┤ĒŖĖ ņłśņ×ģļŗłļŗż.pgpgout/s : ņ┤łļŗ╣ ņŗ£ņŖżĒģ£ņØ┤ ļööņŖżĒü¼ļĪ£ ĒÄśņØ┤ņ¦Ģ ņĢäņøāĒĢ£ ņ┤Ø Ēé¼ļĪ£ļ░öņØ┤ĒŖĖ ņłśņ×ģļŗłļŗż.%vmeff : pgsteal / pgscanņ£╝ļĪ£ Ļ│äņé░ļÉśļŖö ņØ┤Ļ▓āņØĆ ĒÄśņØ┤ņ¦Ć ĒÜīņłś ĒÜ©ņ£©ņä▒ņØś ņ¦ĆĒæ£ņ×ģļŗłļŗż.pgpgin/s ņØ┤ ĻĖēĻ▓®ĒĢśĻ▓ī ņ”ØĻ░ĆĒĢ£ ĒøäņŚÉ Ļ░ÉņåīĒĢśļŖö Ļ▓āņØä ĒÖĢņØĖĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż.pgpgin/s ņØ┤ ņ”ØĻ░ĆĒĢ£ ĒøäņŚÉ Ļ░ÉņåīĒĢśļŖö Ļ▓āņØä ĒÖĢņØĖĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż. ļö░ļØ╝ņä£ 2ņŗ£ļ¦łļŗż cron ņŚÉ ņØśĒĢ┤ ņ¢┤ļ¢ĀĒĢ£ ĒģīņŖżĒü¼(Task)Ļ░Ć ļÅÖņ×æĒĢ£ļŗżĻ│Ā ņČöņĖĪĒĢ┤ ļ│╝ ņłś ņ׳ņŖĄļŗłļŗż.%vmeff Ļ░ÆņØ┤ 100% ļśÉļŖö 0%ņŚÉ Ļ░ĆĻ╣īņÜ┤ ņłśņ╣śļź╝ ĻĖ░ļĪØĒĢ®ļŗłļŗż. ļ¬©ļōĀ ĒÄśņØ┤ņ¦Ćļź╝ ĒÜīņłśĒĢśļŖö ņāüĒā£ļŖö 100% ņØ┤Ļ│Ā, ĒÄśņØ┤ņ¦Ć ņŖżņ║öņØ┤ ņŚåļŖö Ļ▓ĮņÜ░ņŚÉļŖö 0% ņ£╝ļĪ£ Ēæ£ņŗ£ļÉśļ»ĆļĪ£ ļ®öļ¬©ļ”¼ ĒĢĀļŗ╣ ņÜöņ▓ŁņØä ĒĢśņśĆņØä ļĢī ņøÉĒĢśļŖö ņŗ£Ļ░ä ļé┤ņŚÉ ņ▓śļ”¼ļÉśņŚłļŗżĻ│Ā ļ│╝ ņłś ņ׳ņŖĄļŗłļŗż.ņ¦üņĀä paging ļŹ░ņØ┤ĒāĆņŚÉņä£ņØś pgpgin/s , pgpgout/s ņØ┤ ļ░£ņāØĒĢśļŖö Ļ▓āņ£╝ļĪ£ ļ│┤ņĢä, ņČöĻ░ĆņĀüņ£╝ļĪ£ memory ņÖĆ disk Ļ░äņØś I/O ņĀĢļ│┤ļź╝ ĒÖĢņØĖĒĢ┤ ļ│┤Ļ▓ĀņŖĄļŗłļŗż.-b ņśĄņģźņ£╝ļĪ£ I/O ņĀäņåĪļźĀ ĒåĄĻ│äļź╝ ĒÖĢņØĖĒĢ┤ ļ│╝ ņłś ņ׳ņŖĄļŗłļŗż.
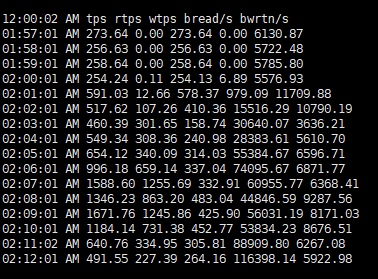
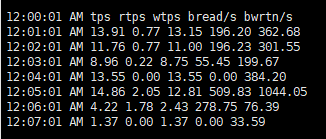
tps : ļ¼╝ļ”¼ņĀü ņןņ╣śņŚÉ ļ░£Ē¢ēļÉ£ ņ┤łļŗ╣ ņ┤Ø ņĀäņåĪ ņłśņ×ģļŗłļŗż. ņŚ¼ĻĖ░ņä£ ņĀäņåĪņØĆ ļ¼╝ļ”¼ņĀü ļööņŖżĒü¼ņŚÉ ņÜöņ▓ŁĒĢ£ I/OņØ┤ļŗżrtps : ļ¼╝ļ”¼ņĀü ņןņ╣śņŚÉ ļ░£Ē¢ēļÉ£ ņ┤łļŗ╣ ņ┤Ø ņØĮĻĖ░ ņÜöņ▓Ł ņłśņ×ģļŗłļŗż.wtps : ļ¼╝ļ”¼ņĀü ņןņ╣śņŚÉ ļ░£Ē¢ēļÉ£ ņ┤łļŗ╣ ņ┤Ø ņō░ĻĖ░ ņÜöņ▓Ł ņłśņ×ģļŗłļŗż.bread/s : ņ┤łļŗ╣ ļĖöļĪØ ļŗ©ņ£äļĪ£ ņןņ╣śņŚÉņä£ ņØĮņØĆ ņ┤Ø ļŹ░ņØ┤Ēä░ ņ¢æņ×ģļŗłļŗż.bwrtn/s : ņ┤łļŗ╣ ļĖöļĪØ ļŗ©ņ£äļĪ£ ņןņ╣śņŚÉ ĻĖ░ļĪØļÉ£ ņ┤Ø ļŹ░ņØ┤Ēä░ ņ¢æņ×ģļŗłļŗż.rtpsņÖĆ bread/s Ļ░ÆņØ┤ 2ņŗ£ņŚÉ ņ”ØĻ░ĆĒĢ£ Ļ▓āņØä ĒÖĢņØĖĒĢśņśĆĻ│Ā, ļŗżļźĖ sarĒīīņØ╝ ļśÉĒĢ£ Ļ░ÖņØĆ ņŗ£Ļ░äļīĆņØĖ 2ņŗ£ņŚÉ rtpsņÖĆbread/sļ¦ī ņ”ØĻ░ĆĒĢ£ Ļ▓āņØä ĒÖĢņØĖĒĢśņśĆņŖĄļŗłļŗż. ņØ┤ļ¤¼ĒĢ£ Ļ▓░Ļ│╝ļĪ£ cron ņ£╝ļĪ£ ņŗżĒ¢ēļÉ£ ņ×æņŚģņØ┤ ļööņŖżĒü¼ i/o ņ×æņŚģņØ┤ļØ╝ļŖöĻ▓āņØä ņČöņĖĪĒĢ┤ļ│╝ ņłś ņ׳ņŖĄļŗłļŗż.| ņ£äņØś ļŹ░ņØ┤Ēä░ļōżņØä ņóģĒĢ®ĒĢśņŚ¼ Ļ▓░ļĪĀņØä ļé┤ļ│┤ļ®┤, ļ®öļ¬©ļ”¼ ņé¼ņÜ® ņĀĢļ│┤(-r)ņŚÉņä£ļŖö ĒŖ╣ņØ┤ĒĢ£ ļ│ĆĒÖöļ¤ēņØĆ ņŚåņŚłĻ│Ā, Swap Out ņØ┤ Ļ▒░ņØś ļ░£ņāØĒĢśņ¦Ć ņĢŖņØĆ Ļ▓āņ£╝ļĪ£ ļ│╝ ļĢī ļ®öļ¬©ļ”¼ ļČĆņĪ▒ĒśäņāüņØ┤ ņŗ£ņŖżĒģ£ņŚÉ ņśüĒ¢źņØä ņżäļ¦īĒü╝ ņ׳ņ¦ĆļŖö ņĢŖņØĆ Ļ▓āņ£╝ļĪ£ ĒīÉļŗ©ļÉ®ļŗłļŗż. ļŗżļ¦ī, ĒÄśņØ┤ņ¦Ģ ņĀĢļ│┤( -B ņśĄņģś) ņÖĆ Block I/OņĀĢļ│┤( -b )ļź╝ ļ┤żņØä ļĢī, 2ņŗ£Ļ▓ĮņŚÉ Block I/O Ļ░Ć ļ¦ÄņØ┤ ņ”ØĻ░ĆĒĢśļ®┤ņä£ paging in/outņØ┤ ņāüļīĆņĀüņ£╝ļĪ£ ļ¦ÄņØ┤ ļ░£ņāØĒ¢łļŗżļŖö Ļ▓āņØä ļ│╝ ņłś ņ׳ņŖĄļŗłļŗż.ņØ┤ļź╝ ļ│╝ ļĢī, ņØ┤ ņŗ£ņĀÉņŚÉ block read I/O ļź╝ ļ¦ÄņØ┤ ļ░£ņāØņŗ£ĒéżļŖö process Ļ░Ć ņłśĒ¢ēļÉśņŚłņØä Ļ░ĆļŖźņä▒ņØ┤ ņ׳ņ¢┤ ļ│┤ņ×ģļŗłļŗż. ņŗżņĀ£ļĪ£ļŖö ĒĢ┤ļŗ╣ ņŗ£ņĀÉņŚÉ ļ░▒ņŚģņØ┤ ņłśĒ¢ēļÉśņ¢┤, ļ¦ÄņØĆ block read I/O Ļ░Ć ļ░£ņāØ ĒĢśņśĆĻ│Ā ĻĘĖļĪ£ ņØĖĒĢ┤ņä£, ļ®öļ¬©ļ”¼ ņé¼ņÜ®ļźĀļÅä ņ¢┤ļŖÉ ņĀĢļÅä ļåÆņĢäņ¦ä Ļ▓āņ£╝ļĪ£ ĒÖĢņØĖņØ┤ ļÉśņŚłņŖĄļŗłļŗż. |
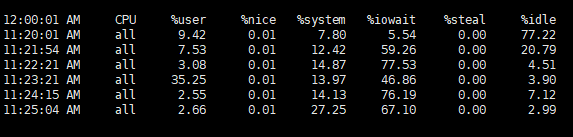
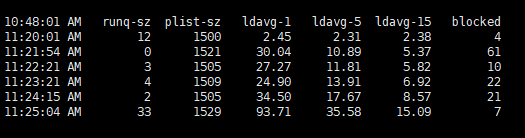
CPU Load HighņØ┤ ņé¼ļĪĆļŖö ņØ╝ņŗ£ņĀüņØĖ load High ļĪ£ ņØĖĒĢ┤, HA ņåöļŻ©ņģśņŚÉņä£ ļ”¼ņåīņŖżĻ░Ć Failover ļÉ£ Ļ▓āņ£╝ļĪ£, sar ļź╝ ĒåĄĒĢ┤ ļ”¼ņåīņŖż ņé¼ņÜ®ļ¤ē ļ│ĆĒÖö ļō▒ņØä ĒÖĢņØĖĒĢśĻĖ░ ņ£äĒĢ┤ņä£ ļČäņäØņØä ņ¦äĒ¢ēĒĢśņśĆņŖĄļŗłļŗż. ņ░ĖĻ│ĀļĪ£, ņØ┤ ņé¼ļĪĆņŚÉņä£ sar ļŖö 1ļČä ļŗ©ņ£äļĪ£ ņłśņ¦æ ļÉśņŚłņŖĄļŗłļŗż.
ņŗ£ņŖżĒģ£ log ņŚÉ CPU Load High ļ®öņäĖņ¦ĆĻ░Ć ņ░ŹĒ׳ļŖö Ļ▓āņØ┤ ĒÖĢņØĖļÉśņ¢┤ņä£, CPU Load ļź╝ ļ©╝ņĀĆ ĒÖĢņØĖĒĢ┤ ļ│┤ņĢśņŖĄļŗłļŗż. -u ņśĄņģśņ£╝ļĪ£ CPU ņé¼ņÜ® ņĀĢļ│┤ļź╝ ĒÖĢņØĖĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż.
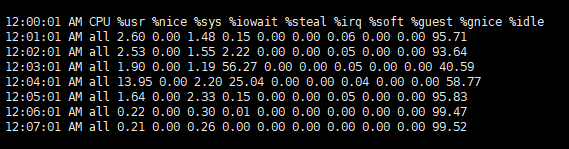
%iowait ņ×ģļŗłļŗż.
%iowait : I/O request ļĪ£ CPU Ļ░Ć ņåīļ╣äĒĢ£ ņŗ£Ļ░äņØä ņØśļ»ĖĒĢśļŖöļŹ░, uniterruptable I/O Ļ░Ć ļ░£ņāØĒĢśļŖö Ļ▓ĮņÜ░ CPU Ļ░Ć ļŗżļźĖ task ņŚÉ ņØśĒĢ┤ ņäĀņĀÉļÉśņ¦Ć ļ¬╗ĒĢśĻ▓ī ļÉ®ļŗłļŗż.CPU ņØś %iowait ņØ┤ ļåÆļŗżļ®┤, ņŗżņĀ£ļĪ£ block I/O Ļ░Ć ļ¦ÄņØ┤ ļ░£ņāØĒĢśņśĆļŖöņ¦Ć ĒÖĢņØĖĒĢ┤ ļ│┤Ļ▓ĀņŖĄļŗłļŗż. -b ņśĄņģśņ£╝ļĪ£ block I/O ņĀĢļ│┤ļź╝ ĒÖĢņØĖĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż.
Memory ļČĆņĪ▒ņØ┤ swap ņé¼ņÜ®ļō▒ņ£╝ļĪ£ ņØ┤ņ¢┤ņĀĖ ļ¼ĖņĀ£Ļ░Ć ļÉĀ Ļ░ĆļŖźņä▒ņØ┤ ņ׳ņŖĄļŗłļŗż. -r ņśĄņģśņØä ĒåĄĒĢ┤ Memory ņé¼ņÜ®ļ¤ēņØ┤ ļåÆņĢśļŖöņ¦Ć ĒÖĢņØĖĒĢ┤ ļ│┤Ļ▓ĀņŖĄļŗłļŗż.
%memused ļÅä ĒÖĢņØĖĒĢśņ¦Ćļ¦ī, kbcached ļź╝ ĒÖĢņØĖĒĢśĻĖ░ļÅä ĒĢ®ļŗłļŗż.
kbcached : ļööņŖżĒü¼ ļō▒ņŚÉņä£ ļ®öļ¬©ļ”¼ļĪ£ ņØĮĒśĆņĀĖ cached ņśüņŚŁņØä ņ░©ņ¦ĆĒĢśĻ▓īļÉ£ Ēü¼ĻĖ░ņ×ģļŗłļŗż.kbactive : ļ╣äĻĄÉņĀü ņĄ£ĻĘ╝ņŚÉ memory ņŚÉ ņś¼ļØ╝ņÖĆņä£, memory reclaim ņŗ£ kbinact ļ│┤ļŗż ļŖ”Ļ▓ī ĒÜīņłśļÉ®ļŗłļŗż.kbinact : kbactive ņŚÉ ļ╣äĒĢ┤ņä£ļŖö ņóĆ ļŹö ņśżļל ņĀäņŚÉ memory ņŚÉ ņś¼ļØ╝ņś© ņśüņŚŁ. ļŗżļźĖ ĒöäļĪ£ņäĖņŖżņØś memory reclaim ņŗ£ ĒÜīņłśļÉĀ Ļ░ĆļŖźņä▒ņØ┤ ļåÆņŖĄļŗłļŗż.ņ£äņŚÉņä£ ļ│Ė CPU, Memory, Block I/O ņĀĢļ│┤ļō▒ņ£╝ļĪ£ļŖö ņŗżņĀ£ļĪ£ ņŗ£ņŖżĒģ£ ļĪ£ļō£Ļ░Ć ļåÆņĢśļŗżĻ│Ā ĒīÉļŗ©ĒĢśĻĖ░ ņ¢┤ļĀżņøĀņŖĄļŗłļŗż.-q ņśĄņģśņ£╝ļĪ£ task ņłśņŚÉ ļīĆĒĢ£ ņĀĢļ│┤ņÖĆ load average ļź╝ ĒÖĢņØĖĒĢ┤ ļ│┤Ļ▓ĀņŖĄļŗłļŗż.
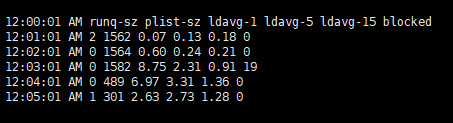
runq-sz : Run queue ĻĖĖņØ┤ļĪ£, ņŗżĒ¢ēļÉśĻĖ░ļź╝ ĻĖ░ļŗżļ”¼Ļ│Ā ņ׳ļŖö task ņłśņ×ģļŗłļŗż.plist-sz : task list ņŚÉ ņ׳ļŖö task ņłśļĪ£ ņĀäņ▓┤ task ņłś ņ×ģļŗłļŗż.blocked : Ēśäņ×¼ blocked ļÉ£ task ņłśļĪ£, I/O complete ļź╝ ĻĖ░ļŗżļ”¼Ļ│Ā ņ׳ļŖö task ļōżņØä ņØśļ»ĖĒĢ®ļŗłļŗż.%iowait ņłśņ╣śņÖĆ ņ¢┤ļŖÉņĀĢļÅä ņØ╝Ļ┤Ćņä▒ņØ┤ ņ׳ņØīņØä ļ│╝ ņłś ņ׳ņŖĄļŗłļŗż.ņØ╝ņŗ£ņĀüņØĖ CPU %iowait Ļ│╝ task ņŚÉņä£ņØś blocked ņłśĻ░Ć ĒÖĢņØĖļÉ®ļŗłļŗż. sar ņØś ņłśņ¦æ interval ņØ┤ 1ļČäņØ┤Ļ│Ā Ēæ£ņŗ£ļÉśļŖö Ļ░ÆļōżņØ┤ 1ļČä ļÅÖņĢłņØś ĒÅēĻĘĀ ņłśņ╣śņØ┤ļŗż ļ│┤ļŗł, ņŗżņĀ£ļĪ£ ņØ┤ņŖłĻ░Ć ņ׳ļŖö ņ¦¦ņØĆ ņł£Ļ░ä ļÅÖņĢłņØĆ ļĪ£ļō£Ļ░Ć ļŹö ļåÆņĢśņØä ņłśļÅä ņ׳ņŖĄļŗłļŗż. sar ļŹ░ņØ┤Ēä░ļ¦īņ£╝ļĪ£ļŖö ĒÖĢņŗżĒĢ£ ļ¼ĖņĀ£ ņøÉņØĖņØä ĒÖĢņØĖĒĢĀ ņłś ņŚåņ¦Ćļ¦ī, VMņŚÉ ĒĢĀļŗ╣ļÉ£ CPU ņłśļź╝ ņóĆ ļŹö ļŖśļĀżņä£ ļ¼ĖņĀ£Ļ░Ć ņÖäĒÖöļÉśļŖöņ¦Ćļź╝ ļ¬©ļŗłĒä░ļ¦üĒĢ┤ ļ│╝ ņłś ņ׳ņØä Ļ▒░ Ļ░ÖņŖĄļŗłļŗż. |
Block I/O ļĪ£ ņØĖĒĢ£ issueņØ┤ ņé¼ļĪĆļŖö ņä£ļ╣äņŖż ĒåĄņŗĀņØ┤ 2ņŗ£Ļ░ä ļŗ©ņ£äļĪ£ ļüŖņ¢┤ņ¦ĆļŖö ĒśäņāüņØ┤ ļ░£ņāØ (ļööņŖżĒü¼ I/O) ĒĢśņŚ¼ sar ļź╝ ĒåĄĒĢ┤ ĒÖĢņØĖĒĢ┤ ļ│┤Ļ│Āņ×É ļČäņäØņØä ņ¦äĒ¢ēĒĢśņśĆņŖĄļŗłļŗż. ņ░ĖĻ│ĀļĪ£, ņØ┤ ņé¼ļĪĆņŚÉņä£ sar ļŖö 10ļČä ļŗ©ņ£äļĪ£ ņłśņ¦æļÉśņŚłņŖĄļŗłļŗż.
-u ņśĄņģśņ£╝ļĪ£ CPU ļČĆĒĢśļź╝ ĒÖĢņØĖĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż.
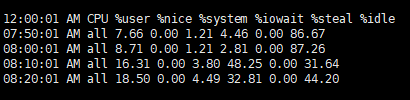
%user,%iowait,%idleņ×ģļŗłļŗż.
%user : ņé¼ņÜ®ņ×É ņłśņżĆ(ņØæņÜ® ĒöäļĪ£ĻĘĖļש)ņŚÉņä£ ņŗżĒ¢ēĒĢśļŖö ļÅÖņĢł ļ░£ņāØĒĢ£ CPU ņé¼ņÜ®ļźĀņ×ģļŗłļŗż. ņØ┤ ĒĢäļō£ņŚÉļŖö Ļ░Ćņāü ĒöäļĪ£ņäĖņä£ļź╝ ņŗżĒ¢ēĒĢśļŖö ļŹ░ ņåīņÜöļÉ£ ņŗ£Ļ░äņØ┤ ĒżĒĢ©ļÉ®ļŗłļŗż.%iowait : ĒöäļĪ£ņäĖņŖżĻ░Ć ļööņŖżĒü¼ I/O ņÜöņ▓Łņ£╝ļĪ£ ļīĆĻĖ░ ņāüĒā£ņŚÉ ņ׳ņŚłļŹś ņŗ£Ļ░äņØś ļ░▒ļČäņ£©ņ×ģļŗłļŗż.%idle : CPUĻ░Ć ņ£ĀĒ£┤ ņāüĒā£ņØ┤Ļ│Ā ņŗ£ņŖżĒģ£ņŚÉ ļ»ĖĻ▓░ ļööņŖżĒü¼ I/O ņÜöņ▓ŁņØ┤ ņŚåļŖö ņŗ£Ļ░äņØś ļ░▒ļČäņ£©ņ×ģļŗłļŗż.%user ņÖĆ %iowait Ļ░Ć ņāüņŖ╣ĒĢśĻ│Ā, %idle Ļ░ÉņåīĒĢśļŖö Ļ▓āņØä ĒÖĢņØĖĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż. -q ņśĄņģśņ£╝ļĪ£ ĒüÉ(run queue) ĻĖĖņØ┤ņÖĆ Load Averagesļź╝ ĒÖĢņØĖĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż.
runq-szņÖĆ blocked ņ×ģļŗłļŗż.
runq-sz : ļ¤░ĒāĆņ×äņŚÉ ņŗżĒ¢ēļÉśĻĖ░ ņ£äĒĢ┤ ļīĆĻĖ░ ņżæņØĖ ĒöäļĪ£ņäĖņŖż ņłśņ×ģļŗłļŗż.blocked : I/O ņÜöņ▓ŁņØ┤ ņÖäļŻīļÉśĻĖ░ļź╝ ĻĖ░ļŗżļ”¼ļŖö ĒöäļĪ£ņäĖņŖż ņłśņ×ģļŗłļŗż.-r ņśĄņģśņØä ĒåĄĒĢ┤ņä£, ļ®öļ¬©ļ”¼ ņĀĢļ│┤ļź╝ ĒÖĢņØĖĒĢ┤ ļ│┤Ļ▓ĀņŖĄļŗłļŗż.

%memused ņ×ģļŗłļŗż. ĒĢäļō£ļź╝ ņäżļ¬ģĒĢśļ®┤,
%memused : Ēśäņ×¼ ņŗ£ņŖżĒģ£ņØś ņĀäņ▓┤ ļ®öļ¬©ļ”¼ ņżæņŚÉ ņé¼ņÜ®ņżæņØĖ ļ®öļ¬©ļ”¼ņØś ļ╣äņ£©ņØä Ēæ£ņŗ£ĒĢ®ļŗłļŗż.%memused ļŖö 99%ņØś ņé¼ņÜ®ļźĀņØä ņ£Āņ¦ĆĒĢśĻ│Ā ņ׳ņŖĄļŗłļŗż.%memused ļŖö ņŗ£ņŖżĒģ£ņØ┤ ņØ╝ņĀĢņŗ£Ļ░ä ļÅÖņ×æĒĢśļ®┤ ļåÆņĢäņ¦ł ņłś ļ░¢ņŚÉ ņŚåļŖö ļČĆļČäņ£╝ļĪ£ ņŗĀĻ▓Įņō░ņ¦Ć ņĢŖņĢäļÅä ļÉśļ®░, kbcached Ļ░ÆņØĆ file cache ļō▒ņ£╝ļĪ£ ņś¼ļØ╝ņÖĆ ņ׳Ļ│Ā, ĒÜīņłś ļÉśņ¢┤ ĒöäļĪ£ĻĘĖļשņŚÉ ĒĢĀļŗ╣ņØ┤ ļÉĀ ņłś ņ׳ļŖö Ļ░Æņ×ģļŗłļŗż. ĻĘĖļ”¼Ļ│Ā ĻĘĖ ņżæ ņ”ēņŗ£ ļ░śĒÖśļÉĀ ņłś ņ׳ļŖö ļČĆļČäņØä kbinactļĪ£ ņāØĻ░üĒĢśņŗ£ļ®┤ ļÉ®ļŗłļŗż.kbinact Ļ░Ć ņŚ¼ņ£ĀĻ░Ć ņ׳ņ£╝ļ®┤, ļ®öļ¬©ļ”¼Ļ░Ć ļČĆņĪ▒ĒĢśņ¦ĆļŖö ņĢŖļŗżĻ│Ā ņČöņĖĪĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż.ļ®öļ¬©ļ”¼ ņé¼ņÜ®ļźĀņØ┤ ļåÆņ£╝ļ»ĆļĪ£, Ēś╣ņŗ£ļéś swap ņśüņŚŁņØä ņé¼ņÜ®ĒĢśļŖöņ¦Ć ĒÖĢņØĖĒĢ┤ ļ│┤Ļ▓ĀņŖĄļŗłļŗż.-S ņśĄņģśņØä ĒåĄĒĢ┤ņä£, swap Ļ│ĄĻ░äņØś ņé¼ņÜ®ļ¤ēņØä ĒÖĢņØĖĒĢ┤ ļ│┤Ļ▓ĀņŖĄļŗłļŗż.
%swpused ņ×ģļŗłļŗż.
%swpused : ņé¼ņÜ®ņżæņØĖ swap ļ®öļ¬©ļ”¼ Ēü¼ĻĖ░%swpusedņØś ļ│ĆļÅÖĒÅŁņØ┤ Ļ▒░ņØś ņŚåņ£╝ļ»ĆļĪ£ SWAPņØĆ ņé¼ņÜ®ĒĢśņ¦Ć ņĢŖļŖöļŗżļŖö Ļ▓āņØä ĒÖĢņØĖĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż.ņ£äņŚÉņä£ņØś -r ņśĄņģśņØä ĒåĄĒĢ£ ļé┤ņÜ®ņØĆ Ēśäņ×¼ ļ®öļ¬©ļ”¼Ļ░Ć ņ░©ņ¦ĆĒĢśĻ│Ā ņ׳ļŖö ņĀĢļÅäļ¦īņØä Ēæ£ņŗ£ĒĢśļ»ĆļĪ£, ņŗżņĀ£ļĪ£ ļ®öļ¬©ļ”¼ņŚÉņä£ņØś I/O Ļ░Ć ņ¢╝ļ¦łļéś ļ¦ÄņØ┤ ļ░£ņāØĒĢśļŖöņ¦ĆļŖö ĒÖĢņØĖņØ┤ ņ¢┤ļĀĄņŖĄļŗłļŗż.
ļ®öļ¬©ļ”¼ņŚÉņä£ņØś paging In/Out ņØä ĒÖĢņØĖĒĢśĻĖ░ ņ£äĒĢ┤, -B ņśĄņģśņØä ņé¼ņÜ®ĒĢ┤ņä£ ĒÖĢņØĖĒĢ┤ ļ│┤Ļ▓ĀņŖĄļŗłļŗż.

pgpgin/s : ņ┤łļŗ╣ ņŗ£ņŖżĒģ£ņØ┤ ļööņŖżĒü¼ņŚÉņä£ ĒÄśņØ┤ņ¦ĢĒĢ£ ņ┤Ø Ēé¼ļĪ£ļ░öņØ┤ĒŖĖ ņłśņ×ģļŗłļŗż.pgpgout/s : ņ┤łļŗ╣ ņŗ£ņŖżĒģ£ņØ┤ ļööņŖżĒü¼ļĪ£ ĒÄśņØ┤ņ¦Ģ ņĢäņøāĒĢ£ ņ┤Ø Ēé¼ļĪ£ļ░öņØ┤ĒŖĖ ņłśņ×ģļŗłļŗż.%vmeff : pgsteal / pgscanņ£╝ļĪ£ Ļ│äņé░ļÉśļŖö ņØ┤Ļ▓āņØĆ ĒÄśņØ┤ņ¦Ć ĒÜīņłś ĒÜ©ņ£©ņä▒ņØś ņ¦ĆĒæ£ņ×ģļŗłļŗż.pgpgin/s ņØ┤ ĻĖēĻ▓®ĒĢśĻ▓ī ņ”ØĻ░ĆĒĢśļŖö Ļ▓āņØä ĒÖĢņØĖĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż.block I/O ļŖö ĒĢ┤ļŗ╣ block device ņØś spec (IOPS , read/write per sec) ļō▒ņØś ĒÖĢņØĖņØ┤ ĒĢäņÜöĒĢśĻĖ░ ļĢīļ¼ĖņŚÉ
-d ņśĄņģśņØä ĒåĄĒĢ┤ ļĖöļĪØ ņןņ╣śņŚÉ ļīĆĒĢ£ ņĀĢļ│┤ļź╝ ĒÖĢņØĖĒĢ┤ ļ│┤Ļ▓ĀņŖĄļŗłļŗż.
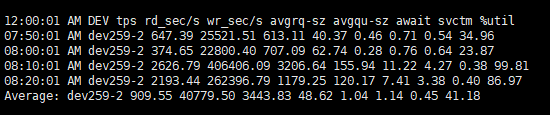
tps : ņןņ╣śņŚÉ ļ░£Ē¢ēļÉ£ ņ┤łļŗ╣ ņĀäņåĪ ņłśļź╝ ļéśĒāĆļāģļŗłļŗż. ņŚ¼ļ¤¼ ļģ╝ļ”¼ņĀü ņÜöņ▓ŁņØä ņןņ╣śņŚÉ ļīĆĒĢ£ ļŗ©ņØ╝ I/O ņÜöņ▓Łņ£╝ļĪ£ Ļ▓░ĒĢ®ĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż.rd_sec/s : ņןņ╣śņŚÉņä£ ņØĮņØĆ ņä╣Ēä░ ņłśņ×ģļŗłļŗż.wr_sec/s : ņןņ╣śņŚÉ ĻĖ░ļĪØļÉ£ ņä╣Ēä░ ņłśņ×ģļŗłļŗż.avgrq-sz : ņןņ╣śņŚÉ ļ░£Ē¢ēļÉ£ ņÜöņ▓ŁņØś ĒÅēĻĘĀ Ēü¼ĻĖ░(ņä╣Ēä░)ņ×ģļŗłļŗż.avgqu-sz : ņןņ╣śņŚÉ ļ░£Ē¢ēļÉ£ ņÜöņ▓ŁņØś ĒÅēĻĘĀ ļīĆĻĖ░ņŚ┤ ĻĖĖņØ┤ņ×ģļŗłļŗż.await : ņ▓śļ”¼ĒĢĀ ņןņ╣śņŚÉ ļ░£Ē¢ēļÉ£ I/O ņÜöņ▓ŁņØś ĒÅēĻĘĀ ņŗ£Ļ░ä(ļ░Ćļ”¼ņ┤ł)ņ×ģļŗłļŗż. ņŚ¼ĻĖ░ņŚÉļŖö ļīĆĻĖ░ņŚ┤ņŚÉ ņ׳ļŖö ņÜöņ▓ŁņŚÉ ņåīņÜöļÉ£ ņŗ£Ļ░äĻ│╝ ņØ┤ļź╝ ņä£ļ╣äņŖżĒĢśļŖö ļŹ░ ņåīņÜöļÉ£ ņŗ£Ļ░äņØ┤ ĒżĒĢ©ļÉ®ļŗłļŗż.%util : ļööļ░öņØ┤ņŖżņŚÉ I/O ņÜöņ▓ŁņØ┤ ņŗżĒ¢ēļÉ£ CPU ņŗ£Ļ░äņØś ļ░▒ļČäņ£©ņ×ģļŗłļŗż(ļööļ░öņØ┤ņŖżņØś ļīĆņŚŁĒÅŁ ņé¼ņÜ®ļźĀ). ņØ┤ Ļ░ÆņØ┤ 100%ņŚÉ Ļ░ĆĻ╣īņÜĖ ļĢī ņןņ╣ś ĒżĒÖöĻ░Ć ļ░£ņāØĒĢ®ļŗłļŗż.tps , rd_sec/s, wr_sec/s, avgrq-sz, avgqu-sz, await, %util Ļ░ÆļōżņØ┤ ņĀäļČĆ ņāüņŖ╣ĒĢ£ Ļ▓āņØä ĒÖĢņØĖĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż.avgqu-sz ļŖö block ņŚÉ ļīĆĒĢ£ IO ĒüÉņŚÉ ņīōņØĖ ņÜöņ▓ŁņØś ĒÅēĻĘĀ ļīĆĻĖ░ņŚ┤ ĻĖĖņØ┤ļĪ£, ņŗ£Ļ░äņŚÉ ļö░ļØ╝ņä£ ņØ┤ Ļ░ÆņØ┤ ļŖśņ¢┤ļéśļ®┤ block IO Ļ░Ć ļ░Ćļ”░ļŗżĻ│Ā ļ│╝ ņłś ņ׳ņŖĄļŗłļŗż.%util ņØĆ block I/O ņŚÉ ņØśĒĢ┤, CPU ņŚÉņä£ ņåīļ¬©ĒĢ£ ņŗ£Ļ░äņØä ņØśļ»ĖĒĢśļ®░, Ļ░ÆņØ┤ ļåÆņ£╝ļ®┤ ņ£äņŚÉ -uņśĄņģśņŚÉņä£ ļ│Ė Ļ▓āņ▓śļ¤╝ iowaitĻ░Ć ļåÆņØä ņłś ņ׳ļŗżĻ│Ā ļ│╝ ņłś ņ׳ņŖĄļŗłļŗż.sar -d ņŚÉņä£ ļ│┤ņĢśļō»ņØ┤ ĒŖ╣ņĀĢ ļööļ░öņØ┤ņŖżņŚÉ %util ņØ┤ Ļ▒░ņØś 100% ņŚÉ Ļ░ĆĻ╣īņøī, I/O Saturation ļ░£ņāØņ£╝ļĪ£ ņä£ļ╣äņŖżņŚÉ ņśüĒ¢źņØä ņŻ╝ņŚłņØä Ļ░ĆļŖźņä▒ņØ┤ ļåÆņŖĄļŗłļŗż.ņä£ļ╣äņŖż ļ¼ĖņĀ£ņØś ļ¬ģĒÖĢĒĢ£ ņøÉņØĖņØ┤ ļ¼┤ņŚćņØĖņ¦ĆļŖö, ņØ┤ļ¤░ ļ”¼ņåīņŖż ņé¼ņÜ®ļ¤ēņØä ņ£Āļ░£ņŗ£ĒéżļŖö process ņŚÉņä£ ņ¢┤ļ¢ĀĒĢ£ ļÅÖņ×æņØä Ē¢łņŚłļŖöņ¦Ćļź╝ ņČöĻ░ĆļĪ£ ĒÖĢņØĖņØ┤ ĒĢäņÜöĒĢ®ļŗłļŗż. |
ļ¼ĖņĀ£ņØś ņøÉņØĖ ļČäņäØņØä ņ£äĒĢ┤, ļ”¼ņåīņŖż ņé¼ņÜ®ļ¤ēņØä ņ¦üņĀæņĀü ļśÉļŖö Ļ░äņĀæņĀüņ£╝ļĪ£ ĒÖ£ņÜ®ĒĢśļŖö Ļ▓āņØä ņĢ×ņØś ņŚ¼ļ¤¼ ņ╝ĆņØ┤ņŖżļź╝ ĒåĄĒĢ┤ņä£ ņé┤ĒÄ┤ ļ│┤ņĢśņŖĄļŗłļŗż.
sar ļéś ļ╣äņŖĘĒĢ£ ņÜ®ļÅäņØś ļÅäĻĄ¼ļōżņØä ņל ĒÖ£ņÜ®ĒĢśĻĖ░ ņ£äĒĢ┤ņä£ ņŗĀĻ▓ĮņŹ©ņĢ╝ ĒĢĀ ļČĆļČäļōżņØ┤ ņ׳ņŖĄļŗłļŗż. ņŻ╝ļĪ£ ļŗżņØī ļé┤ņÜ®ļōżņØä Ļ│ĀļĀżĒĢ┤ņĢ╝ ĒĢ®ļŗłļŗż.
ņŗ£Ļ░äļÅÖĻĖ░ĒÖö – ļČäņäØĒĢĀ ļīĆņāü ļŹ░ņØ┤Ēä░ņØś ņŗ£Ļ░äņĀĢļ│┤Ļ░Ć ņĀĢĒÖĢĒĢ┤ņĢ╝ ĒĢ®ļŗłļŗż. ņŗ£Ļ░äļÅÖĻĖ░ĒÖöĻ░Ć ņĢł ņØ┤ļŻ©ņ¢┤ņĀĖ ņŗ£Ļ░äņØ┤ ĒŗĆņ¢┤ņ¦äļŗżļ®┤ ļŗżļź╝ ņĀĢļ│┤ļōżĻ│╝ ņóģĒĢ®ņĀüņ£╝ļĪ£ ļČäņäØņŗ£ ņ¢┤ļĀżņøĆņØ┤ ļ░£ņāØĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż.ņøīĒü¼ļĪ£ļō£ ĒŖ╣ņ¦Ģ ņØ┤ĒĢ┤ – sar ļ¦īņ£╝ļĪ£ļŖö ļČäņäØņŚÉ ņĀ£ĒĢ£ņØ┤ ņ׳ņØä ņłś ņ׳ņŖĄļŗłļŗż. ņ¢┤ļ¢ż ļ”¼ņåīņŖżļź╝ ņ¢┤ļ¢╗Ļ▓ī ņé¼ņÜ®ĒĢśļŖöņ¦Ćļź╝ ņÜ┤ņśüņ×É ļīĆņāüņ£╝ļĪ£ ņØĖĒä░ļĘ░ĒĢśĻ▒░ļéś, ļÅÖņ×æĒĢśļŖö ņĢĀĒöīļ”¼ņ╝ĆņØ┤ņģśņØ┤ ņ¢┤ļ¢ż ņĀ£ĒÆłņØĖņ¦Ć ĒÖĢņØĖĒĢśņŚ¼ ņøīĒü¼ļĪ£ļō£ļź╝ ņ¦Éņ×æĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż.ļŗżļźĖ ļĪ£ĻĘĖļōż – ņŗ£ņŖżĒģ£ ļĪ£ĻĘĖļéś Ļ░Éņé¼ļĪ£ĻĘĖ, ņĢĀĒöīļ”¼ņ╝ĆņØ┤ņģśņØś ļĪ£ĻĘĖļōżņŚÉ ĻĖ░ļĪØļÉśļŖö ņŚÉļ¤¼ļōżņØĆ ņ¢┤ļ¢ĀĒĢ£ ļ”¼ņåīņŖżĻ░Ć ļ¼ĖņĀ£ņ×äņØä ņĢīļĀżņŻ╝ļŖö Ē×īĒŖĖĻ░Ć ļÉśĻĖ░ļÅä ĒĢ®ļŗłļŗż.Interval, sampling – sarņØś Ļ▓ĮņÜ░ ļ”¼ņåīņŖż ļŹ░ņØ┤Ēä░ ņłśņ¦æ Ļ░äĻ▓®ņØ┤ 10ļČäņ×ģļŗłļŗż. ņØ┤ Ļ▓ĮņÜ░ ņØ┤ņŖł ļ░£ņāØ ņŗ£ņĀÉņØä ĒżĒĢ©ĒĢśļŖö 10ļČäĻ░äņØś ļłäņĀü ļŹ░ņØ┤Ēä░Ļ░Ć ĻĖ░ļĪØļÉśļ»ĆļĪ£, ļ”¼ņåīņŖż ņé¼ņÜ®ņØ┤ ņŖżĒīīņØ┤Ēü¼ņä▒ņ£╝ļĪ£ ņ¦¦ņØĆ ņŗ£Ļ░ä ņØ╝ņŗ£ņĀüņ£╝ļĪ£ ņ╣śņå¤ņĢśļŗżĻ░Ć ļ¢©ņ¢┤ņ¦ĆļŖö Ļ▓ĮņÜ░ļØ╝ļ®┤ ņłśņ╣śĻ░Ć ļåÆņ¦Ć ņĢŖņĢä ņŗØļ│äņØ┤ ņ¢┤ļĀżņÜĖ ņłśļÅä ņ׳ņŖĄļŗłļŗż. ĻĘĖļ¤¼ļ»ĆļĪ£ ņĀüļŗ╣ĒĢ£ ņŗ£Ļ░ä Ļ░äĻ▓®ņ£╝ļĪ£ ņĪ░ņĀĢĒĢ┤ņĢ╝ ĒĢ®ļŗłļŗż.ņ£ä ļ│Ėļ¼ĖņŚÉņä£ ņé┤ĒÄ┤ļ┤żļō»ņØ┤ sar ļĪ£ ņĢäļל ņĀĢļ│┤ļōżņØä ĒÖĢņØĖĒĢĀ ņłś ņ׳ņŖĄļŗłļŗż.
ļ”¼ļłģņŖż ņä£ļĖīņŗ£ņŖżĒģ£ļōżņØś ņĀäņ▓┤ņĀüņØĖ ņĀĢļ│┤ļź╝ ĒÖĢņØĖĒĢĀ ņłś ņ׳ņŚłņ¦Ćļ¦ī, ņĢäļלņÖĆ Ļ░ÖņØĆ ĒŖ╣ņĀĢ ļČĆļČäņØś ņĀĢļ│┤ļŖö ĒÖĢņØĖĒĢĀ ņłś ņŚåņŚłņŖĄļŗłļŗż.
sar ļÅäĻĄ¼ļ¦īņ£╝ļĪ£ļŖö ļ¼ĖņĀ£ņØś ņøÉņØĖ ļČäņäØņØ┤ ņ¢┤ļĀżņÜĖ ņłś ņ׳ņ£╝ļ®░, ņØ┤ļ¤¼ĒĢ£ Ļ▓ĮņÜ░ sar ļŹ░ņØ┤Ēä░ļź╝ ĒåĄĒĢ┤ ņČöĻ░ĆļĪ£ ļČäņäØĒĢ┤ņĢ╝ ĒĢĀ ļ”¼ņåīņŖż ļīĆņāü ļ▓öņ£äļź╝ ņóüĒ׳Ļ│Ā ĒĢ┤ļŗ╣ ļ”¼ņåīņŖż ļČäņäØņŚÉ ĒŖ╣ĒÖöļÉ£ ļÅäĻĄ¼ļź╝ ņé¼ņÜ®ĒĢ┤ņĢ╝ ĒĢĀ Ļ▓āņ×ģļŗłļŗż.
process ļ│ä ņĀĢļ│┤ļŖö pidstat ļ¬ģļĀ╣ņ£╝ļĪ£, systemcall ļō▒ņØś ņČöņĀüņØĆ strace Ļ░ÖņØĆ trace ļÅäĻĄ¼ļĪ£, network ļŖö netstat ņØ┤ļéś tcpdump/tshark ļō▒ņØ┤ ņ׳ņŖĄļŗłļŗż.
ļ¦żņÜ░ ļŗżņ¢æĒĢ£ ļÅäĻĄ¼Ļ░Ć ņ׳ņ£╝ļ»ĆļĪ£, ĒÖśĻ▓ĮĻ│╝ ļ¬®ņĀüņŚÉ ļ¦×ļŖö ļÅäĻĄ¼ļź╝ Ļ│©ļØ╝ ņé¼ņÜ®ĒĢĀ ĒĢäņÜöĻ░Ć ņ׳ņŖĄļŗłļŗż.
ņØ┤ļ▓ł ĻĖĆņŚÉņä£ļŖö sar ļź╝ ņé┤ĒÄ┤ļ│┤ņĢśņŖĄļŗłļŗż.
ņŗ£ņŖżĒģ£ ņÜ┤ņśü ļ░Å ļČäņäØņØ┤ ĒĢäņÜöĒĢ£ ļČäļōżņŚÉĻ▓ī ļÅäņøĆņØ┤ ļÉśļŖö ĻĖĆņØ┤ ļÉśņŚłņ£╝ļ®┤ ĒĢ®ļŗłļŗż.
ļŗżņØīņŚÉļŖö ņóĆ ļŹö ņ×¼ļ»Ėņ׳ņ£╝ļ®┤ņä£(?) ņēĮĻ│Ā(?) ņ£ĀņØĄĒĢ£ ļé┤ņÜ®ņØś ņŻ╝ņĀ£ļĪ£ ņ×æņä▒ĒĢ┤ ļ│┤Ļ▓ĀņŖĄļŗłļŗż.
Ļ░Éņé¼ĒĢ®ļŗłļŗż.